
Určenie typu kávy, teda či ide o robustu, arabiku alebo mix, je pre mnohých kávových nadšencov dôležité z viacerých dôvodov.
Poznanie tohto rozdielu pomáha pri posudzovaní kvality, chuti a charakteristík kávy, čo v konečnom dôsledku ovplyvňuje celkový zážitok z pitia kávy. Prvým dôvodom je, že rôzne odrody kávy, majú odlišný pôvod, pestovateľské podmienky a spôsob spracovania. Arabika je považovaná za kvalitnejšiu. Má jemnejšiu chuť, kyslosť a bohatšiu arómu. Na druhej strane, robusta je odrodou kávy, ktorá je menej náročná na pestovanie a má väčšiu odolnosť voči chorobám. Má silnejšiu chuť, vyššiu hladinu kofeínu a tvorí základ pre mnoho espresso zmesí. Okrem toho, odroda kávy môže mať vplyv aj na obsah kofeínu. Robusta má obvykle vyšší obsah kofeínu ako arabika. Pre niektorých ľudí je dôležité poznať obsah kofeínu v káve, aby mohli upraviť svoju spotrebu podľa individuálnych potrieb a tolerancie.
A vy ste už rozmýšľali niekedy nad tým, aká je dobrá káva? Ako viem ja, bežný kávičkár a nie zrovna nadšenec, overiť zloženie kávy, ktorú dennodenne pijem? Či sú pomery arabiky a robusty naozaj také, aké sú uvedené na obale? Či pijem 100% arabiku, do ktorej nie je namiešaná lacnejšia rousta? Existuje na túto problematiku nejaké overiteľné riešenie?
Coffelysis – tím študentov z FIIT STU v rámci predmetu Tímový projekt – strávil rok práve riešením tejto problematiky – ako vieme zistiť zloženie kávy, ak máme k dispozícii iba pár gramov praženej zrnkovej kávy?
Bázou nášho riešenia je iónový spektrometer, ktorého výstupom sú spektrá, ktoré potom vieme analyzovať v našej aplikácii, a na základe dát predpovedať zloženie kávy – či daná vzorka obsahuje 100% arabiku, 100% robustu, resp. mix týchto dvoch druhov káv.
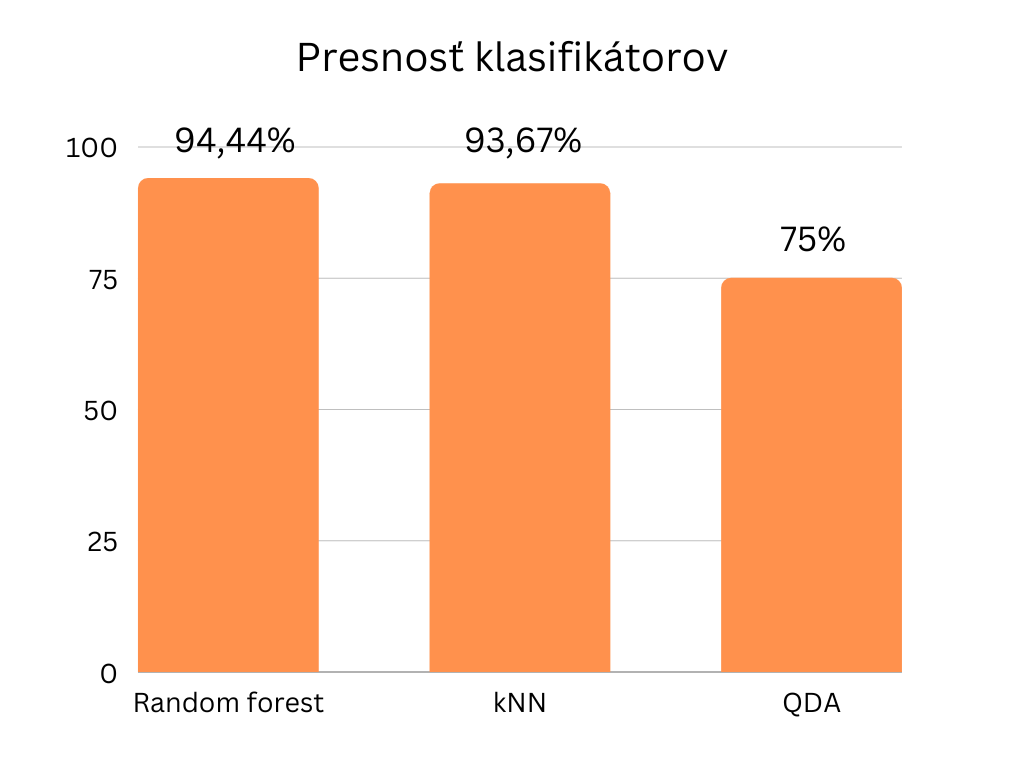
Ďalším dôležitým komponentom nášho riešenia je machine learning – naše klasifikátory dosahujú presnosť 94,44% – Random Forest, 93,67% – kNN a 75% – QDA. Nakoľko na klasifikáciu kávy iónovým spektrometrom neexistujú voľne dostupné datasety, vzali sme veci do vlastných rúk, a vyrobili vlastný dataset. Vzorky kávy sme dôkladne pomleli, vyrobili vzorky a namerali vzorky iónovým spektrometrom. Pomocou týchto meraní sme už vedeli natrénovať klasifikátory.
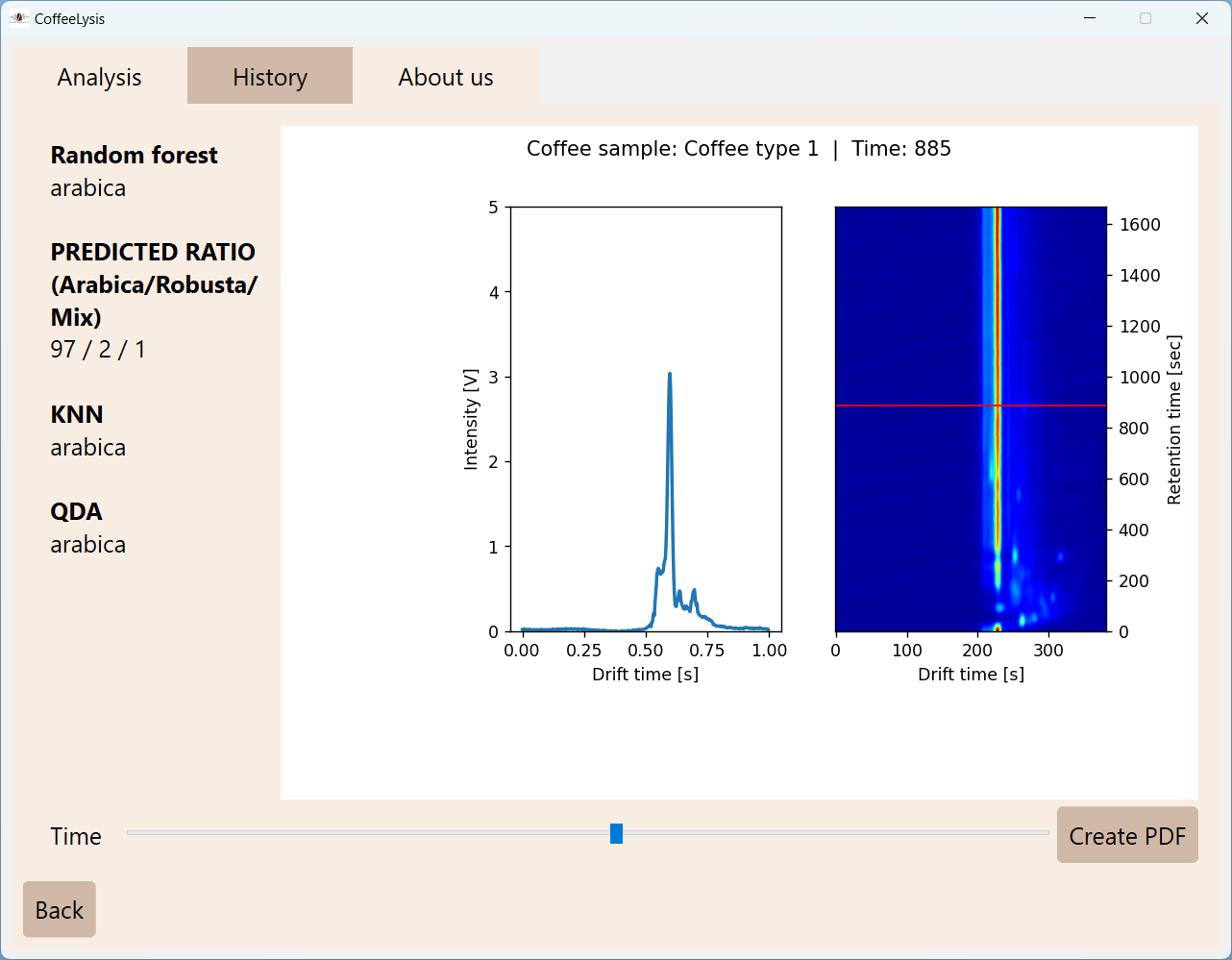
Aby koncový používateľ – napríklad pražiareň – mal možnosť pohodlne pracovať s natrénovanými klasifikátormi, vytvorili sme ľahko používateľnú desktopovú aplikáciu. Táto aplikácia má za úlohou spracovať výstupný súbor zo spektrometra, spracovať dáta uložené vo výstupnom súbore, a následne vyhodnotiť druh kávy na základe spracovaných dát. Aplikácia taktiež umožňuje si vytvoriť zoznam predošlých meraní a generovať PDF súbory s výsledkom merania.
Máme aj priestor na zlepšenie nášho riešenia, a to pomocou určenia pomerov vo vzorke – momentálne máme v datasete mix 50:50 (arabica / robusta), ale s väčším datasetom by sme mohli predikovať aj pomery vzorky, napríklad 90:10, 80:20, atď. Projekt vyvíjame ako tím študentov Fakulty Informatiky a Informačných Technológií STU v zložení Bc. Dávid Branný, Bc. Tomáš Both, Bc. Peter Demeter, Bc. Štefan Dudaško, Bc. Kristián Escher, Bc. Tibor Galambos a Bc. Filip Slimák pod pedagogickým vedením Mgr. Martina Saba, PhD., a v spolupráci so spoločnosťou MaSaTECH. Taktiež ďakujeme pražiarniam Ebenica Coffee a 9 Grams Coffee za poskytnutie vzoriek na analýzu.