Ľudstvo dnes generuje ohromné množstvo dát a aj keď je to takmer neuveriteľné, ich objem sa zdvojnásobí zhruba každé dva či tri roky. Inak povedané, za každú takto smiešnu hŕstku rokov vygenerujeme viac dát, než ľudstvo vygenerovalo za celú svoju doterajšiu históriu. Takáto dátová explózia však neznamená len éru informácií, ale aj éru Big Data. Ten, kto bude tie najväčšie objemy cenných dát spracovávať a podarí sa mu v nich odhaliť skryté súvislosti, si otvorí dvere k jednému z najväčších pokladov 21. storočia.
Koľkokrát ste si s výkrikom uvedomili, že ste sa mohli vyhnúť nejakej nepríjemnej udalosti, ak by k vám dorazila včas tá správna informácia? Ak by ste vedeli, že ten kameň sa hýbe, nikdy by ste naň neskočili a nezvrtli si nohu. Ak by ste vedeli, že sú na tej ulici zápchy, vyhli by ste sa jej a nemuseli by ste sa hodinu zdržať. Ak by ste vedeli, že to dieťa zbehne z chodníka, začali by ste brzdiť o sekundu skôr a všetko by bolo inak. Odhalenie jedinej dôležitej informácie môže od základu zmeniť výsledok aj veľmi zložitého procesu. Vonkoncom pri tom nepotrebujete byť veštec. V mnohých prípadoch bohato stačí, aby sa k vám dostali informácie o udalostiach, ktoré sa už udiali alebo sa práve dejú.
[tit_citation color=“#7d2727″ padding=“20px“ float=“left“ font-size=“1.2em“]“Rozsiahlejšie dáta nás často prekvapia poznatkom, že naše predstavy vychádzajúce z malých či obmedzených dátových objemov boli nesmierne skreslené“[/tit_citation]
Big Data nie je nejako striktne definovaný pojem. Podobne ako v prípade cloudu, aj s pojmom Big Data súvisí množstvo výrazne odlišných softvérových a hardvérových technológií. V základe sa však pod týmto pojmom skrýva súbor dát, ktorý je taký veľký a komplexný, že ho nie je možné analyzovať a spracovávať tradičnými metódami (napr. pomocou klasických databázových tabuliek). To však nejakú jasnú predstavu väčšine ľudí nedáva, a preto je omnoho užitočnejšia predstava, ktorú použil Viktor Mayer-Schönberger z Oxfordskej univerzity vo svojej knihe Big Data: Revolúcia, ktorá zmení to, ako žijeme, pracujeme a myslíme. Mayer odporučil, aby sme o Big Data uvažovali jednoducho ako o veciach, ktoré nikdy nebolo možné robiť v malom meradle, avšak náhle sa stávajú realizovateľné v tom veľkom meradle. Inak povedané, ak je súprava dát obrovská a prakticky úplná, je možné z nej extrahovať poznatky, o ktorých sa nám predtým ani nesnilo.
Čím viac dát, tým lepšie. Rozsiahlejšie dáta nás často prekvapia poznatkom, že naše predstavy vychádzajúce z malých či obmedzených dátových objemov boli nesmierne skreslené. Pekná ukážka tohto javu je napríklad obľuba tradičného amerického kruhového koláča, ktorý si ľudia kupujú v zmrazenej podobe a následne doma dopečú. Ak ste sa v minulosti spýtali amerických obchodných reťazcov, akú príchuť majú Američania najradšej, odpoveď bola triviálna. Majú najradšej jablkový, pretože prevaha predajov tejto príchuti je drvivá a ostatné varianty sú doslova na okraji záujmu. Jedného dňa však došlo k zaujímavej udalosti. Okrem veľkej verzie s priemerom 30 cm začali obchody predávať aj menšie s priemerom 11 cm a obľuba jablkovej verzie náhle letela strmo dolu o niekoľko pozícií. Do popredia sa drali slivkové, malinové a iné príchute. Ako je to možné? Ukázalo sa, že staré poznatky o najobľúbenejšom koláči boli skreslené obmedzenými dátami. Ľudia v skutočnosti preferovali iné príchute, avšak pri 30 cm verzii, ktorá sa kupovala pre celú rodinu, sa museli všetci zhodnúť a jablkovú príchuť obvykle všetci akceptovali. Príchuť jablka „nikoho neurazila“ a bola skoro u každého ako ďalšia v poradí, takže dostala prednosť. Slivkový síce otcovi chutil najviac, ale syn ho nemal rád, zatiaľ čo malinový chutil matke a dcére, ale otec ho neznášal. Pri kúpe malej verzie koláča, určenej pre jedného, si každý mohol vybrať príchuť, akú naozaj chcel. Malé dáta nás tak o popularite jablkového koláča oklamali.
Peňažné poklady ukryté v dátach
Masívne objemy dát „tolerujú“ analýzy, pri ktorých sme sa v menších objemoch potápali ku dnu, zavalený nepresnosťami. Obrovská súprava rôznorodých dát totiž fluktuáciu a nedostatky jediného merania úspešne potlačí. Je to možné vnímať ako speváka, ktorý z pódia skočí na skupinku troch ľudí a bolestivo spadne na zem. Ak to ale urobí na koncerte a skočí do davu, more rúk ho bez problémov udrží a môže na nich plávať ako na vodnej hladine.
Ako dobrý príklad z praxe môže slúžiť gigantický e-shop Amazon, ktorý je dnes okrem iného najväčším predajcom kníh na svete. Keď v 90. rokoch minulého storočia začínal, zamestnával armádu recenzentov a kritikov, ktorí hodnotili a recenzovali knižný obsah a pomáhali ľudom s výberom. To obchodu poskytovalo značnú výhodu, pretože ľudia mohli vidieť pri recenziách jednej knihy odporučenia na iné podobné knihy, ktoré sami nečítali, ale kritik už áno. Títo recenzenti, známi aj ako „Amazon Voice“, výrazne ovplyvňovali to, aké knihy sa najviac predávali. Na konci 90. rokov však Amazon začal špekulovať s myšlienkou, že by zákazníkom začal knihy odporúčať účinný automatický mechanizmus. Ten by pri tom nevychádzal len z hlúpeho ponúkania kníh z rovnakej kategórie, ale z toho, aké knihy si zákazník v minulosti kúpil. Dnes to síce považujeme za samozrejmé, ale v tej dobe to bola novátorská myšlienka. Amazon začal zbierať o zákazníkoch značné množstvo dát, pričom ukladal nielen to, ktoré knihy si zákazník kúpil, ale aj to, na ktoré sa v e-shope pozeral ale nekúpil, ako dlho sa na ne pozeral a či sa k nim v budúcnosti znovu vrátil.
Systém odporúčaní založený na Big Data dnes generuje Amazonu až tretinu ziskov
Ak by zberali dáta len od stovky či tisícov zákazníkov, sieť súvislostí by bola plná fluktuácií a osobných preferencií a bola by taká nepresná, že by bola nanič. Dáta od desiatok či dokonca stoviek miliónov ľudí, to však bola celkom iná káva. Amazon sa sprvu snažil hľadať podobných zákazníkov, v snahe riešiť problém štýlom „vrana k vrane sadá“, avšak výsledky neboli príliš dobré. Prešiel teda k prístupu, pri ktorom sa namiesto ľudí začal zaujímať o produkty ako také, pričom sa zameral na to, s čím sa nakupovala kniha A, s čím kniha B a ako často sa to dialo. Takáto analýza odhaľovala zaujímavé súvislosti, pričom šlo napríklad o to, že ak si ľudia kúpili produkt X a Y, tak v 50 % prípadov si kúpili aj produkt Z. Z pohľadu Amazonu šlo o zásah do čierneho, pretože takáto informácia sa dá využiť a akonáhle niekto dal do košíka produkt X a Y, mohol mu systém ponúknuť produkt Z sám. Ak následne úspešnosť zakúpenia produktu stúpla z 50 % na 75 %, bolo jasné, že systém fungoval. Tak sa aj stalo a automatický systém okamžite generoval omnoho väčšie množstvo nákupov ako tím recenzentov a Amazon toto oddelenie v roku 2001 rozpustil. Alternatívou k nemu sa stali len používateľské hodnotenia. Je pri tom nutné si uvedomiť, že systém nebol a nie je tvorený žiadnou umelou inteligenciou, múdrejšou ako človek. Systém ako taký je celkom „hlúpy“ a vôbec netuší, prečo si ľudia kupujú knihu od jedného autora spolu s knihou druhého autora. To je nepodstatné. Stačí odpozorovať súvislosti a využiť ich. Dnes systém odporúčaní generuje Amazonu až tretinu ziskov a na podobné metódy narazíte na mnohých e-shopoch a službách, vrátane Netflixu či YouTube.
[tit_citation color=“#731818″ padding=“20px“ float=“left“ font-size=“1.2em“]“Z pohľadu obchodníkov sú v rozsiahlych dátach ukryté poklady, ktoré čakajú na objavenie“[/tit_citation]
Z pohľadu obchodníkov sú v rozsiahlych dátach ukryté poklady, ktoré čakajú na objavenie, pričom záznamy, ktoré na prvý pohľad pôsobia jednoúčelovo, môžu vo veľkom rozsahu odhaliť celkom nové spojenia a významy. Peter Norvig, vývojár umelej inteligencie Googlu, to pekne prirovnal k obrázkom. Ak sa pozriete na 17 000 rokov staré maľby koňa v jaskyniach vo francúzskom Lascaux, v základe nie sú až také odlišné od dnešnej fotografie. Fotografia je pochopiteľne detailnejšia, ale stále technicky odhaľuje tú istú vec – momentku v čase. Podobne je to aj s jednoduchými alebo podrobnými dátami, ktoré sú stále rovnako tupé. Akonáhle ale vstúpi do procesu dynamika a správne spracovanie, situácia sa mení. Ak dokážeme odfotiť 25 snímok za sekundu a následne ich takto rýchlo prehrať, z fotky sa stáva video, čo celkom zmení povahu odhalenej informácie.
Obchodný reťazec Target z dát o nákupe dokázal vyextrahovať informácie, ktoré indikujú, že nakupujúca žena je práve tehotná
Na ukážku takejto zmeny povahy dát nám môže slúžiť príhoda, ktorá sa udiala vo veľkom americkom obchodnom reťazci Target (podobný systému Tesco). V ňom sa v roku v roku 2012 odohral prípad, ktorý je dodnes žiarivou ukážkou sily Big Data. Target, podobne ako iné reťazce, zbiera o svojich zákazníkoch množstvo dát, pričom ho zaujíma, čo kupujú a ako často, podľa čoho im v budúcnosti ponúka rôzne zľavy a kupóny (podobne ako to Tesco robí prostredníctvom svojej zákazníckej karty, pomocou ktorej nákup k zákazníkovi priraďuje). Zákazníci sú tak lákaní k opätovnému nákupu. Jedného dňa do Targetu vbehol rozhorčený otec a dožadoval sa okamžitého stretnutia s manažérom predajne. V ruke pritom mával letákmi, ktoré obchod zaslal na meno jeho dcéry, navštevujúcej strednú školu. Otca rozčúlilo, že obchod jej začal posielať kupóny na kojeneckú výbavu, detské oblečenie a iné produkty pre čerstvých rodičov. V jeho očiach obchod jeho dcéru navádzal k tomu, aby sa stala v tak mladom veku matkou.
Čerství rodičia sú pre predajcov tohto typu veľmi cenní, pretože nakupujú veľké množstvo vecí. V momente ako sa rodičmi stanú a začnú nakupovať je však už často neskoro, pretože môžu dať prednosť konkurencii. Obchodu by veľmi pomohlo, ak by o tehotenstve vedel a mohol budúcim rodičom ponúknuť kupóny či lákavé zľavy v tesnom predstihu, čím by ich k sebe nalákal. Analytická divízia Targetu sa tak podujala zistiť, či by takúto informáciu nebolo možné vyextrahovať z dát, ktoré majú. Zaujímali ich nielen stovky tisíc zákazníkov, ktorí takéto produkty nakupovali, ale hlavne ženy, ktoré sa zaregistrovali do programu pre detské darčeky. V USA majú vo zvyku usporadúvať „baby shower“, teda oslavu novorodenca, pri ktorom priatelia a rodina nakúpi pre bábätko množstvo darčekov a daruje ich rodičom (podobne ako v prípade svadobných darov). Matky pri tom využívajú ponuku obchodov, ktoré umožňujú v predajniach čítačkou kódov vytvoriť zoznam, čo by chceli dostať a ich rodina a priatelia si následne zoznam v obchode môžu vyžiadať a nakupovať veci podľa neho.
[tit_citation color=“#613d3d“ padding=“20px“ float=“left“ font-size=“1.2em“]“Google si uvedomil, že odpoveď nie je v malých dátach, pri ktorých sa používalo len jednoduché porovnávanie výrazov so slovníkom. Chybne zadané výrazy, ktoré iné firmy považovali za odpad, sa stali pri masívnych objemoch pokladom“[/tit_citation]
Target teda začal spracovávať dáta o nákupoch týchto zákazníčok, pričom algoritmami analyzoval dáta z posledných mesiacov a snažil sa odhaliť spojitosti. Ukázalo sa, že staré nákupy čerstvých matiek vykazovali špecifické znaky, ktoré tehotenstvo môžu prezradiť. Napríklad okolo tretieho mesiaca tehotenstva si mnoho žien začalo kupovať neparfumované krémy, zatiaľ čo o pár týždňov zas rôzne vitamíny, ako napríklad kalcium, zinok či magnézium. Šlo o niekoľko desiatok špecifických produktov a ich časová postupnosť umožnila vytvoriť mechanizmy, ktoré predpovedali, že daný zákazník je zrejme tehotný a začali mu automaticky posielať reklamné ponuky v súvislosti s budúcim privedením potomka na svet. Dáta boli také presné, že dokonca umožnili vytvoriť aj očakávaný dátum pôrodu čo umožnilo rozosielať špecifické ponuky na kupóny a akcie v jednotlivých štádiách tehotenstva. V príbehu s otcom, ktorému sa venoval reportér New York TImes, Charles Duhigg, došlo práve k takému prípadu. Target to vyriešil tak, že sa otcovi ospravedlnil za chybu a nepatričné konanie. O niekoľko dní dokonca otec dostal ospravedlňujúci telefonát od vyššieho manažmentu obchodu, avšak ukázalo sa, že situácia sa zmenila. Otec už sa na obchod vôbec nehneval a priznal, že po rozhovore s dcérou sa dozvedel, že je naozaj tehotná a obchodu sa tentoraz sa ospravedlnil on sám.
Rozpoznávame preklepy aj choroby
Aj keď v Big Data ležia poklady najmä v súvislosti s predajom a jednotlivé firmy z nich túžia vyťažiť návod na zvýšenie svojho zisku, bolo by veľmi krátkozraké vnímať túto problematiku len z tohto uhla. Stačí sa len pozrieť na ohromné množstvo spôsobov, ako nazbierané dáta používa Google. Výbornou ukážkou je jeho funkcia opráv v rámci vyhľadávača. Tá je prítomná aj v slovenskej verzii, avšak jej obrovská sila je viditeľná najmä v tej anglickej. Tento systém bol za roky prevádzky vytrénovaný tak, že pripomína až mágiu. Je až neuveriteľné, akú „hatmatilku“ dokáže na vstupe Google akceptovať a ponúknuť správnu verziu ako ten najlepší veštec. Dáta sa pri tom stále zlepšujú, pretože na ponuku „mali ste na mysli“ môžete odpovedať kliknutím, alebo zmenou výrazu, čo ponúka nové a cenné dáta, použiteľné v budúcnosti. Google túto bezkonkurenčne najlepšiu kontrolu a opravu písaných výrazov získal pri tom prakticky „zdarma“. Stačilo ukladať to, čo ľudia zadávali, ako sa opravovali a na čo klikali. Ak je slovo nerozpoznané, ľudia ho pri následnom druhom pokuse opravia a tak to robia až dovtedy, dokým nenájdu správnu podobu. Google tak získava dáta o tom, aká je správna odpoveď a čo pôvodná hatmatilka mala znamenať. Na rozdiel od svojich predchodcov (ako bol na začiatku 90. rokov Yahoo či Alta Vista), si Google uvedomil, že odpoveď nie je v „malých dátach“, pri ktorých sa používalo len jednoduché porovnávanie výrazov so slovníkom. Chybne zadané výrazy, ktoré iné firmy považovali za odpad, sa stali pri masívnych objemoch naopak pokladom, z ktorých bolo možné behom rokov ukovať bezkonkurenčne najvýkonnejší systému tohto typu.
Dátové centrá Googlu patria k najväčším na svete
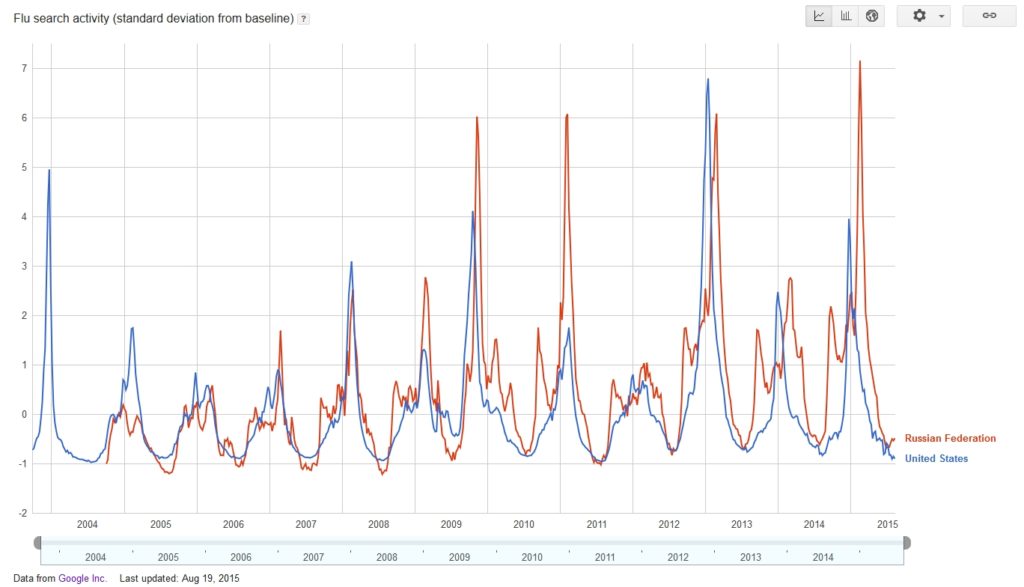
Google ťahá dáta z vyhľadávača v skutočnosti omnoho ďalej a ťažba informácií je často celkom vzdialená od toho, čo by bežný človek očakával. Vďaka svojej dominantnej pozícii internetového vyhľadávača má k dispozícii miliardy zadaných vyhľadávacích výsledkov denne, pričom všetky sú uložené na jeho serveroch, pripravené na analýzu. Nielenže mu v počte zbieraných dát tohto typu len málokto konkuruje, tento internetový gigant má dostatok serverových prostriedkov a špičkových vývojárov na to, aby ich dokázal úspešne spracovať. Ako ďalší dobrý príklad použitia Big Data môže slúžiť rok 2009, s ktorým si určite spojíte mediálne veľmi známy vírus H1N1, popisovaný aj ako prasacia chrípka. Centrum na kontrolu a prevenciu chorôb (CDC) vydalo v USA vyhlásenie, pri ktorom doktorov inštruovalo o reportovaní každého prípadu chrípky, aby bolo možné sledovať, ako sa choroba šíri. Problémom bolo, že akýkoľvek obraz pandémie bol vždy zastaraný, často o niekoľko týždňov. Nešlo pri tom len o problém zhromažďovaní hlásení, ale aj o to, že ľudia často prichádzajú k doktorovi s niekoľkodenným oneskorením , keď sa choroba už plne prejavila. V tom čase však vývojári Googlu publikovali v prestížnom vedeckom žurnále Nature nesmierne zaujímavú štúdiu o tom, ako na základe obrovského objemu dát z vyhľadávača môžu predpovedať šírenie klasickej chrípky v USA, ktorá prepukne vždy s príchodom jesene, respektíve zimy. V štúdii Google demonštroval, ako je možné vytvárať podrobné mapy šírenia nielen na celkové štáty, ale aj menšie regióny, mestá či mestské oblasti. Všetko je možné odpozorovať z toho, čo ľudia hľadajú.
[tit_citation color=“#8f2b2b“ padding=“20px“ float=“left“ font-size=“1.2em“]“Pomocou analýzy kartových transakcií v reálnom čase Visa za posledný rok zabránila krádeži 2 miliárd eur“[/tit_citation]
Vyhľadávacie frázy mohli byť rôzne, pričom ľudia hľadali napríklad príznaky chrípky, alebo lieky proti kašľu a teplote. Google skrátka zobral 50 miliónov najhľadanejších výrazov a porovnal ich so zaznamenanými štatistikami CDC v rokoch 2003 a 2008. Pokúšali sa nájsť pri tom koreláciu medzi jednotlivými výrazmi a šírením chrípky, respektíve aké výrazy sa objavili tesne pred tým. Použili pri tom viac ako 450 miliónov rôznych matematických modelov. Ukázalo sa, že 45 výrazov veľmi dobre predpovedalo výsledky z rokoch 2003 až 2006, čo poslúžilo na vybudovanie schémy a modelu, ktorý následne otestovali na rokoch 2007 a 2008. Vo výsledku tak Google dokázal úspešne vytvárať mapy šírenia chrípky, avšak nie s niekoľkodňovým, alebo dokonca týždňovým oneskorením, ako má CDC na základe reportov doktorov, ale prakticky v reálnom čase. Práca nie je na konci a systém je nutné kalibrovať, pretože reporty médií často spustia „falošnú paniku“, následkom čoho ľudia hľadajú výrazy, aj keď sú zdraví. Dáta je však v týchto súvislostiach možné zohľadniť a čerpať z výsledkov cenné informácie o rozsahu aktuálnej nákazy. Dáta z predošlých rokov sú voľne dostupné a môžete ich vidieť na adrese www.google.org/flutrends. Súčasné dáta poskytuje Google pre CDC.
Rozšírenia chrípky v USA a Rusku v posledných rokoch v podobe predikcie Googlu
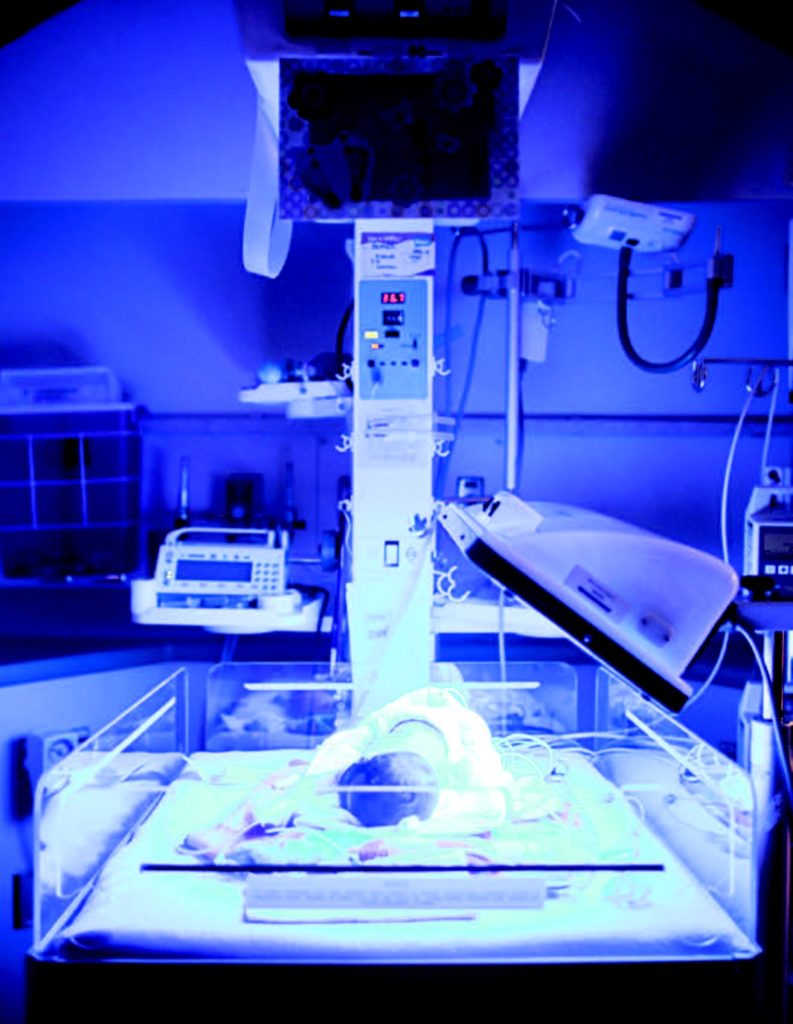
Big Data budú čoskoro hrať nepochybne veľkú rolu v zdravotníctve. Ako príklad súčasného použitia sa dá uviesť projekt Artemis, ktorý v roku 2009 rozbehlo Kanadské združenie pre inováciu, IBM a nemocnica v Toronte. Zamerali sa pri tom na špecializované monitorovacie stanice predčasne narodených detí. Tie zaznamenávajú veľké množstvo dát (napr. tep, frekvenciu dýchania, hladinu kyslíka v krvi), avšak žiadny človek nedokáže vnímať stovky či tisíce meraní za sekundu, takže personál zvyčajne len pravidelne preberá výsledky napríklad každú hodinu a zapisuje ich do karty. Dáta pritom vníma oddelene, pre každého pacienta zvlášť. Tím preto experimentálne napojil 200 takýchto zariadení na neustály záznam všetkých dát a následne ich začal porovnávať, snažiac sa tak odhaliť rôzne korelácie medzi všetkými deťmi. Až 20 % takýchto predčasne narodených detí dostane infekciu a šestina nakazených za ňu zaplatí aj životom, takže hľadanie širších súvislostí je nesmierne cenné. Tie najzaujímavejšie poznatky sa však podarí v Big Data odhaliť obvykle až v momente, keď je objem dát skutočne veľký a postupom rokov sa projekt uchytil do niekoľkých nemocníc a ďalej sa rozširuje, zbierajúc tak dáta pomocou pripojenia na cloud. V takýchto prípadoch nazbieranie obrích rozmanitých dát skrátka trvá.
Predpovedáme samovraždy, poruchy a zločin
Big Data nie je o nič menej zaujímavé ani v bankovom sektore, pretože účinná analýza obrovského množstva dát sa môže stať užitočným nástrojom na boj s podvodmi. V súčasnosti sú napríklad veľmi rozšírené karty s bezkontaktnými čipmi, ktoré umožňujú vykonávať rýchlo a bezstarostne malé nákupy (napr. do 20 eur), bez zadania ochranného kódu. Pri krádeži karty teda zlodej namiesto veľkého nákupu vykonáva rýchlo malé nákupy v rôznych lokalitách, obvykle tesne pod týmto limitom. Takéto správanie je však zvyčajne veľmi neštandardné, na rozdiel od bežného správania zákazníka a ak sú všetky dáta neprestajne analyzované, túto anomáliu je možné zbadať a kartu vyradiť často aj o niekoľko hodín skôr ako si majiteľ všimne, že mu ju niekto ukradol aj s peňaženkou. Ide o niečo, čo by pri neskoršej analýze, alebo analýze len malej vzorky dát, skrátka nebolo možné. Mnoho finančných inštitúcií, ako napríklad Mastercard či Visa, tieto mechanizmy úspešne zaviedlo a ďalej ich zlepšujú. Visa napríklad uvádza, že tieto systémy pomohli včasnou detekciou podvodov ušetriť za posledný rok až 2 miliardy eur.
UPS sa o svoj zástup viac ako 60 000 vozidiel stará masívnou analýzou dát
Inú tvár Big Data ukazuje doručovacia služba UPS, ktorá v USA svoju flotilu viac ako 60 000 vozidiel vybavila GPS modulmi, ktoré umožňujú podrobné monitorovanie polohy a rýchlosti jednotlivých automobilov. Tieto dáta následne analyzuje a používa na vytvorenie predikčného modelu porúch. V minulosti firma používala len klasické meranie na základe ubehnutého času a niektoré súčiastky menila po dvoch či napríklad troch rokoch. To však bolo neefektívne, pretože mnohé boli ešte v dobrom stave, zatiaľ čo iné už spôsobili poruchu auta a oneskorenie rozvozu. Analýza kompletných GPS dát umožňuje rátať počet zastavení a rozbehnutí auta a takisto merať dosahovanú rýchlosť, čo spolu s analýzou teplotných a iných senzorov poslúžilo pre odhalenie toho, kedy súčiastky v priemere najviac zlyhávajú. Dnes ich firma mení len v prípade, že dané auto túto métu dosiahne a kým pre jedno môže ísť napríklad o dobu 1,5 roka, iné ju dosiahne až za dvojnásobnú dobu. Výsledkom je značná finančná úspora. Tá však nie je jediná a z dát je možné extrahovať aj efektivitu jednotlivých trás. Spracovaním obrovského množstva dát z GPS bola UPS schopná trasy optimalizovať a nasledujúci rok ušetrila 50 miliónov prejdených kilometrov.
[tit_citation color=“#911010″ padding=“20px“ float=“left“ font-size=“1.2em“]“Systém predpovedania zločinu pomohol v cieľových lokalitách znížiť počet vlámaní o 33 %, počet napadnutí o 21 % a poškodzovanie majetku o 12 %“[/tit_citation]
Tieto príklady dobre demonštrujú to, že Big Data je možné použiť na odhalenie toho, kedy, kde a čo sa deje, pričom nie vždy je nutné odhaliť to, prečo sa to deje. Už prvá verzia odpovede totiž dokáže šetriť, alebo zarobiť milióny dolárov. Nemusí ísť pravdaže len o peniaze a analýza Big Data môže zachraňovať aj ľudské životy. Veľká nádej sa vkladá do analýz príspevkov na Twitteri, Facebooku či iných sociálnych sieťach, ktoré potenciálne môžu odhaliť korelácie a vzory, vedúce k samovražde či v USA, žiaľ, strašidelne častej streľbe na školách. V roku 2014 vykonal austrálsky Národný inštitút pre duševné zdravie, v spolupráci s univerzitou v New South Wales, štúdiu (Detecting suicidality on Twitter), pri ktorej bolo z Twitteru extrahovaných 14 701 tweetov, ktoré obsahovali kľúčové slová indikujúce to, že daná osoba uvažuje o samovražde. Často ide o plané poplachy a výskumný tím preto oddelil náhodne 2000 tweetov a nechal ich klasifikovať odborníkmi. Celkom 14 % z príspevkov odborníci klasifikovali ako veľmi vážne, 56 % ako potenciálne vážne a 29 % ako obsah, ktorý je bezpečne možné ignorovať. Názory však nie sú vždy totožné a ľudia sa vo svojom hodnotení zhodovali v priemere v 76 % prípadov. Následne boli dáta použité na vytvorenie automatického detekčného mechanizmu, čím sa overilo, či by dané rozpoznávanie mohlo byť vykonávané aj automaticky. Systém v priemere trafil 80 % tweetov, ktoré ľudia označili za veľmi vážne a následne sa pri ďalších pokusoch a vzorkách stále viac zlepšoval, až napokon dosiahol zhodu s ľuďmi.
To je potenciálne veľmi dobrý výsledok, pretože automatický mechanizmus by mohol spracovávať úplne všetky dáta na Twitteri, čo pri ľudskom tíme nie je možné a upozorňoval by na potenciálne problémy. V tomto prípade však neboli použité dáta, z ktorých bolo jasné, ktorý používateľ sa o samovraždu naozaj pokúsil. Systém teda len súhlasil s ľuďmi, že niečo má varovné signály. Ak by bolo možné získať dáta osôb, ktoré sa naozaj o samovraždu pokúsili, mohli by sme odhaliť znaky, ktoré žiadnemu človeku nie sú na prvý pohľad zrejmé. Podobne ako sme na začiatku článku spomenuli odhalenie prvkov v súvislosti s nákupmi tehotných žien, môžeme potenciálne na sociálnych sieťach analyzovať príspevky ľudí, ktorí si vzali život a hľadať špecifické prvky. Akonáhle budú dáta skutočne veľké, je možné zbadať vzory a zvýšenú pravdepodobnosť nejakej udalosti a upozorniť napríklad krízovú linku, ktorá by sa prípadom mohla zaoberať, zhodnotiť ho a navrhnúť pomoc, bez toho, aby sa dotyčný jedinec vôbec dozvedel, že na počiatku detekcie bol automatický systém.
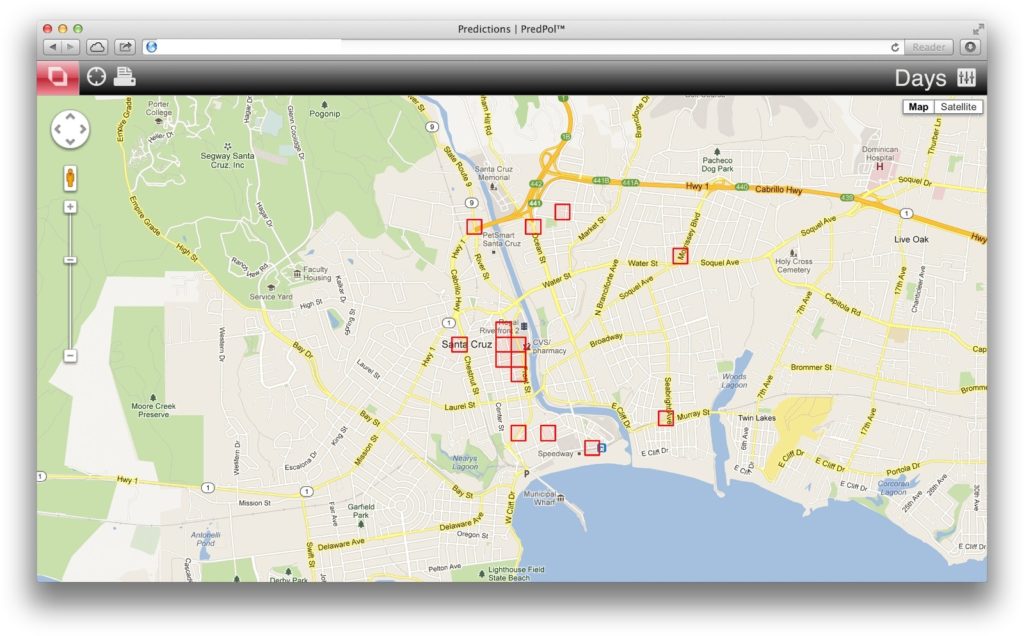
Jeffrey Brantingham pred mapou predpovedaného zločinu v Los Angeles
Pamätáte sa na sci-fi film Minority Report, v ktorom vďaka špeciálnym zmutovaným osobám mohlo policajné oddelenie predpovedať nadchádzajúci zločin a zastaviť ho tesne predtým, ako sa stal? Podobné veci by bolo možné dosiahnuť aj s pomocou Big Data. Zatiaľ síce nejde o strašidelnú vec, že by sme niekoho obviňovali z nespáchaného zločinu, ale o predikciu, kde k nejakej nezákonnej udalosti môže dôjsť. Ak by sme napríklad analyzovali obrovské množstvo vlámaní, napadnutí a iných trestných činov, bolo by možné odhaliť potenciálny čas a lokalitu, kedy je pravdepodobnosť vzniku takejto udalosti vysoká a vyslať tam napríklad policajnú hliadku. Tá by páchateľa mohla chytiť pri čine, alebo by naopak svojou prítomnosťou danej udalosti zabránila.
Presne takýto systém bol úspešne testovaný a je aj dnes nasadený v Los Angeles. Stojí za ním Jeffrey Brantingham, ktorý so svojím tímom z Kalifornskej univerzity aplikoval matematické modely nadáta reportov policajného zboru. Pri analýze obrovského množstva záznamov si totiž môžeme všimnúť, že na nejakom mieste v danú hodinu dochádza k nelegálnej činnosti častejšie, prípadne, že inde je vidieť korelácia zločinov s nejakou inou udalosťou. Výsledný model bol následne ponúknutý so softvérom na skúšku polícii v Los Angeles. Test prebiehal po dobu 21 mesiacov (v rokoch 2013 až 2015), pri ktorých bola pozícia hliadok plánovaná na základe daného modelu. Policajti v aute skrátka sledovali displej s mapou, na ktorom videli červené štvorčeky a postupne dané lokality obhliadali, pričom prípadne na nich zostali do doby, než to program vyžadoval. Už v prvých mesiacoch zločinnosť v daných oblastiach poklesla o 7,4 % (bez toho, aby sa počet hliadok alebo jázd zvýšil) a policajný zbor Los Angeles ho začal v rokoch 2014 a 2015 aplikovať nielen v troch experimentálnych divíziách, ale aj v 11 ďalších (celkovo je Los Angeles rozdelené na 21 takýchto divízií). Systém v priebehu testovania dokázal v cieľových lokalitách výrazne zlepšiť situáciu a počet vlámaní poklesol o 33 %, napadnutí o 21 % a poškodzovanie majetku o 12 %. Je tak dosť dobre možné, že sa onedlho objaví v teste aj v ďalších mestách.
Mapa predpovedaného zločinu ako ju vidia príslušníci polície
Nebezpečenstvo nielen z hľadiska súkromia
Schopnosť zbierať objemné množstvá najrôznejších dát sa môže stať novou „menou“ 21. storočia. Dnes, v rámci osobných dát používateľov, hrajú prvé husle jednoznačne Google a Facebook, avšak iné firmy silou mocou chvátajú za nimi, ako by išlo o nový ekvivalent zlatej horúčky. To v budúcnosti môže byť značne problematické v súvislosti s konkurenčným bojom. Ak sa dnes postavíte proti zabehnutej konkurencii a pokúsite sa vytvoriť lepší produkt, bojujete s ekonomicky silnejšou firmou a jej zabehnutou značkou, čo je samo o sebe dosť ťažké. V budúcnosti sa ale méta presiahnutia produktu takejto spoločnosti môže stať úplne nemožnou, pretože bude používať extrémne efektívne mechanizmy, založené na analýze masívneho množstva dát od stoviek miliónov či dokonca miliárd používateľov, čo žiadna nová spoločnosť nebude môcť simulovať. Je nepochybné, že postupne firmy vďaka rozmanitosti Big Data analýz objavia spojenia a súvislosti, ktoré nikomu, kto tieto dáta nemá, nebudú vôbec zrejmé.
[tit_citation color=“#c92020″ padding=“20px“ float=“left“ font-size=“1.2em“]“Schopnosť zbierať objemné množstvá najrôznejších dát sa môže stať novou menou 21. storočia“[/tit_citation]
V posledných rokoch sme sa dostali do éry „datafikácie“ pričom zbierame dáta, ktoré boli v minulosti celkom nedostupné. Pri pohľade na ne by zbledla závisťou zrejme aj bývala východonemecká Stasi, ktorá je dodnes považovaná za najefektívnejšiu tajnú službu v histórii (zbierala cez sieť informátorov veľké množstvo podrobných informácií o každom občanovi NDR). Kým štátne orgány mali v minulosti podrobné záznamy o mene, dátumoch narodenia, bydlisku či fotografie osôb, dnešné IT spoločnosti majú vytvorenú aj sieť celej rodiny a priateľov, prehľad o názoroch, záujmoch a každodenných činnostiach. Zbierajú dáta o tom, kde ľudia relaxujú, nakupujú, čo nakupujú, čo pozerajú a kde pracujú (nemusíte to vôbec do svojho profilu vypĺňať, dá sa to odvodiť z dát, kde sa zdržujete v špecifickú časť dňa, s kým komunikujete a podobne). Všetko doplnené o časté fotografie a textové vyjadrenia, ktoré je možné kombinovať s neprestajným zaznamenávaním polohy GPS snímačom v mobilnom zariadení, ktoré prezradí, kde daný človek bol, kde je, kam mieri a kto je okolo neho. Do toho všetkého sa dnes pridávajú zdravotné dáta o tepe, teplote, fyzických činnostiach a podobne (sedíte, stojíte, kráčate, bežíte). Našťastie, obvykle sú tieto rôznorodé dáta vo vlastníctve rôznych firiem len čiastočne.
Cieľom komerčných spoločností pravdaže nie je ľudom ublížiť a ani ich ohrozovať, ako tomu bolo v prípade Stasi, ale poskytovať im službu a produkt, čo im umožňuje zarobiť peniaze. To však môže časom s poctivým správaním kolidovať a dnes skrátka vôbec netušíme, čo v takto rozsiahlych dátach môžeme odhaliť. V článku Nebezpečenstvo filtračnej informačnej bubliny (TOUCHIT Apríl/2016) sme napríklad poukázali na úspešné experimenty s manipulovaním politických preferencií, alternovaním výsledkov vyhľadávania. Takéto nebezpečenstvá pritom s rozširovaním pokročilých analýz v rámci Big Data budú stále väčšie.
Projekt Artemis sa vydal cestou analýzy dát predčasne narodených detí, v snahe objaviť indikácie nadchádzajúcich problémov, čo by umožnilo včasnú reakciu
Všetko to môže viesť k veľkým benefitom a takisto rizikám. Analýza neprestajne zaznamenávaných zdravotných dát z vašich zariadení môže jedného dňa umožniť to, že vám v prípade vysokej šance na infarkt smarthodinky odporučia presunúť sa urýchlene do nemocnice. Dáta dokážu potlačiť zločinnosť, zlepšiť produkty, zabránia strate na životoch, či vám rôzne uľahčia život. Na druhú stranu vás ale môžu takisto pripraviť o prácu (zamestnávateľ analýzou zistí, že žena je pravdepodobne tehotná, skôr ako to zistí ona sama, a prepustí ju), či o slobodné rozhodnutie, pri ktorom ste zmanipulovaní k niečomu len vďaka tomu, že má niekto o vás dostatok dát.
Big Data sú na tom podobne ako autá, počítače a internet. Aj tie majú predovšetkým pozitíva, avšak negatíva je možné nájsť vždy. Bolo by hlúpe snažiť sa presadiť zákaz áut, pretože umožňujú ľahký transport zločincom pri kriminálnej činnosti, či zakazovať internet, pretože ho podvodníci používajú na okrádanie nevinných ľudí. Analýza Big Data má obrovský potenciál k zneužitiu, a preto je nutné s nekalými činnosťami bojovať a snažiť sa ich obmedzovať. Riešením ale nie je plošný zákaz, rovnako ako je nezmyslom vypínať internet. Pozitíva sú skrátka priveľké a zmena je tu. Musíme preto reagovať na meniacu sa situáciu a upraviť zákony i postoje.
Ľudia budú Big Data sledovať s nadšením, ak bude Google vyhľadávač stále lepší, ak im Netflix odporučí vhodné filmy, ak Facebook či Twitter zabráni samovražde, alebo smart zariadenie zachráni niekomu život včasnou detekciou choroby. Nikdy sa im ale nebude páčiť, ak niekto analýzu zneužije proti nim na zákerný typ marketingu (napr. zneužívajúci slabé chvíľky, pri ktorých systém zistí, že ste náchylní na nákup cukríkov v depresii a bude vám ju podsúvaním negatívneho obsahu úmyselne vyvolávať). Manipuláciu s týmito citlivými dátami je nutné neprestajne sledovať a nekalé jednanie je nutné tvrdo trestať.Tento článok vyšiel aj v tlačenom júnovom vydaní TOUCHIT č. 5/2016, preto sa niektoré skutočnosti uvedené v článku, môžu odlišovať oproti aktuálnemu dátumu publikovania.