Kedykoľvek, keď plánované alebo neplánované servisné odstávky vo firmách prerušia ich obchodnú činnosť, všetci prehrávajú: spoločnosti prichádzajú o čas a peniaze, no a poskytovatelia služieb strácajú dobrú povesť.
Keď je server nedostupný, nezáleží všeobecne príliš na tom, či je odstavený plánovane alebo ide o poruchu. Prerušenia činnosti stoja peniaze koniec koncov aj vtedy, keď boli vopred oznámené.
Preto je cenné preskúmať detailnejšie túto problematiku. V tomto článku sa bližšie pozrieme na dôvody vedúce k odstávkam a následne preskúmame ak technické možnosti ako odstávky skrátiť. Pri skúmaní týchto otázok je samozrejmé, že za každých okolností musí byť chránená bezpečnosť systémov.
Plánované odstávky
Rozlišujeme dva druhy odstávok – plánované a neplánované. K plánovaným odstávkam dochádza zvyčajne v čase pevne vyhradenom pre údržbu. Pri určovaní časového rozvrhu je nutné zohľadniť požiadavky mnohých rôznych účastníkov, aby bolo zaručené, že údržba bude čo najmenej kolidovať s obchodnou činnosťou spoločnosti. Obvykle sa robí cez víkend, aby koordinácia medzi zainteresovanými stranami mohla byť minimálna. Frekvencia vykonávania údržby závisí od mnohých faktorov. Podľa druhu firmy môže prebiehať každý mesiac, ale aj raz ročne. V daných časových oknách prebiehajú administratívne úkony údržby na softvéri, hardvéri alebo priamo na samotných dátových centrách.
Pokiaľ ide o softvér, dôvodom odstávky môžu byť zmeny v systéme alebo konfigurácii aplikácií, ale častejšie sú nutné kvôli aktualizáciám softvéru. Tie vyžadujú inštalácie nových softvérových balíčkov na zavedenie nových funkcií a odstránenie alebo opravy softvérových defektov. Odstraňovanie chýb v softvéri môže byť vyžadované aj legislatívne – napríklad v prípade, že firma spracúva informácie o kreditných kartách a musia dodržiavať bezpečnostné štandardy PCI.
Hardvérová údržba je často spájaná s výrazom „Mean Time Between Failures“ (MTBF, čo znamená stredná či priemerná doba bezporuchovej prevádzky), ktorý administrátorov vedie k presvedčeniu, že môžu použiť stochastické metódy na výpočet, kedy konkrétne zlyhá súčasť hardvéru. V niektorých oblastiach môže byť tento prístup prínosný, ale nie je možné sa naň úplne spoliehať. Časové okno vyhradené pre údržbu hardvéru sa preto využíva na výmenu pokazených súčastí, napríklad pevných diskov, procesorov alebo pamäťových modulov. Niekedy sa hardvér vymieňa aj napriek tomu, že ešte nie je defektný, ale podľa údajov histórie systému by si odstávku čoskoro vyžiadal. Vo vyhradenom čase môže tiež dôjsť k úplnej výmene celého uzavretého systému – napríklad jednotky na ukladanie dát.
Čas vyhradený na údržbu samozrejme ponúka príležitosť aj pre práce na infraštruktúre alebo na samotnom dátovom centre. Medzi ďalšie činnosti, ktoré možno vykonávať v čase pridelenom údržbe, patrí práca na sieťovej infraštruktúre, čistenie klimatizácie, kontrola protipožiarneho systému a všeobecné opravné práce na budove.
Spoločnosti, ktoré prevádzkujú svoje vlastné dátové centrá, sa pri údržbe nemôžu vyhnúť plánovaným odstávkam. Jediné, čo môžu minimalizovať, je frekvencia a dĺžka údržbových prác. Pomôcť im môžu riešenia na automatizáciu úkonov alebo ich paralelné vykonávanie, ako napríklad SUSE Manager na úrovni operačného systému alebo SAP Landscape Virtualization Management pre prostredie SAP. Takéto spoločnosti však stále čelia dileme: zatiaľ čo niektoré úkony údržby je nutné vykonávať zriedkavo, je naopak nevyhnutné (predovšetkým s ohľadom na bezpečnostné hrozby) vykonávať často aktualizácie infraštruktúry dátového centra. Ani vtedy, keď využívajú len hostiteľské riešenie alebo verejný cloud, tento problém úplne nezmizne. V takýchto prípadoch je údržba jednoducho prenesená na poskytovateľa služby – tieto úkony vykonáva poskytovateľ cloudu alebo hostingu, odstávky ako také však zostanú. Plánované odstávky môžu byť prinajlepšom minimalizované na základe dobre postavených zmlúv o poskytovaní služieb, ale úplne sa im nedá vyhnúť.
Neplánované odstávky
Ako je zrejmé z ich označenia, neplánované odstávky jednoducho nemožno predvídať. Dochádza k nim podľa slávneho Murphyho zákona: neplánované odstávky prakticky vždy nastanú v tom najhoršom čase. Našťastie takmer v každom možnom scenári existuje aspoň jedna technológia, ktorá v prípade núdze pomôže problém vyriešiť.
Ak napríklad dôjde k výpadku napájania, môžu pomôcť záložné zdroje energie, akumulátorové súpravy a diesel agregáty. Ak zlyhá pevný disk, systémy RAID zaistia, aby dáta ostali dostupné a chybné pevné disky je možné jednoducho vymeniť počas plánovanej údržby. Systémy na rozloženie záťaže umožňujú, aby systém mohol pracovať ďalej aj vtedy, keď odíde jedna alebo viac jeho súčasťou – teda ak tieto „load balancers“ podporuje aj daná aplikácia. Funkcia RAS (Reliability, Availability, Serviceability, čiže Spoľahlivosť, Dostupnosť a Opraviteľnosť) operačný systém upozorní na chyby procesora a pamäťových modulov. Naopak, v prípade, že kvôli zmene konfigurácie alebo inštalácii záplat dôjde k porušeniu rovnováhy systému, možno ho uviesť do predchádzajúcej podoby, v ktorej bolo overené, že funguje bez problémov. Vďaka stavu, kde sú veľmi rozšírené scenáre zachovania dostupnosti a systémy rozloženia záťaže, nemusia byť služby dotknuté ani v prípade, že zlyhajú všetky komponenty. A virtualizácia umožňuje účinne reagovať nielen v prípade vysokej vyťaženosti zdrojov, ale ak je správne nastavená, aj pri zlyhaní celého fyzického hostiteľa.
Čo však môžete robiť s chybami softvéru? Všetko, čo môžu administrátori urobiť, je dodávať pravidelné opravné záplaty, čo nie je ľahké urobiť bez reštartovania aplikácie alebo systému. Avšak nové technológie môžu poskytnúť pomocnú ruku.
Vyššia bezpečnosť s kratšími odstávkami – paradox?
Je možné zaručiť vyššiu bezpečnosť a súčasne minimalizovať odstávky? Než budeme riešiť tento zjavný paradox, pozrime sa na skutočnú prípadovú štúdiu: linuxové jadro. Plátanie (patching) linuxového jadra vyžaduje nielen reštartovanie spustených aplikácií – čo za určitých okolností môže byť ospravedlniteľné – ale aj celého systému, či už ide o fyzického hostiteľa alebo virtuálny počítač. Plátaniu jadra sa však vyhnúť nedá. Len v priebehu desiatich mesiacov od novembra 2015 do septembra 2016 hlásil web Národnej databázy zraniteľnosti (National Vulnerability Database – NVD) (https://nvd.nist.gov/) celkom 22 bezpečnostných dier v linuxovom jadre, ktorých skóre CVS bolo 6 alebo vyššie, čo znamená, že boli klasifikované ako vysoko nebezpečné. Tu je ich zoznam:
CVE-2013-7446
CVE-2015-6937
CVE-2015-7872
CVE-2015-7990
CVE-2015-8019
CVE-2015-8539
CVE-2015-8660
CVE-2015-8709
CVE-2015-8812
CVE-2015-8816
CVE-2016-0728
CVE-2016-0758
CVE-2016-0774
CVE-2016-1583
CVE-2016-2053
CVE-2016-2384
CVE-2016-3134
CVE-2016-4470
CVE-2016-4565
CVE-2016-4997
CVE-2016-5829
CVE-2016-6480
V tejto grafike sú (ku 15. septembru 2016) vybrané náhodné dni, kedy sme sa pozreli na linuxové jadro. Je nutné podotknúť, že reportované bezpečnostné chyby sú prítomné v akomkoľvek linuxovom jadre, či už prichádzajú od SUSE, Red Hat, Ubuntu, Debian, Gentoo alebo akejkoľvek inej distribúcie.
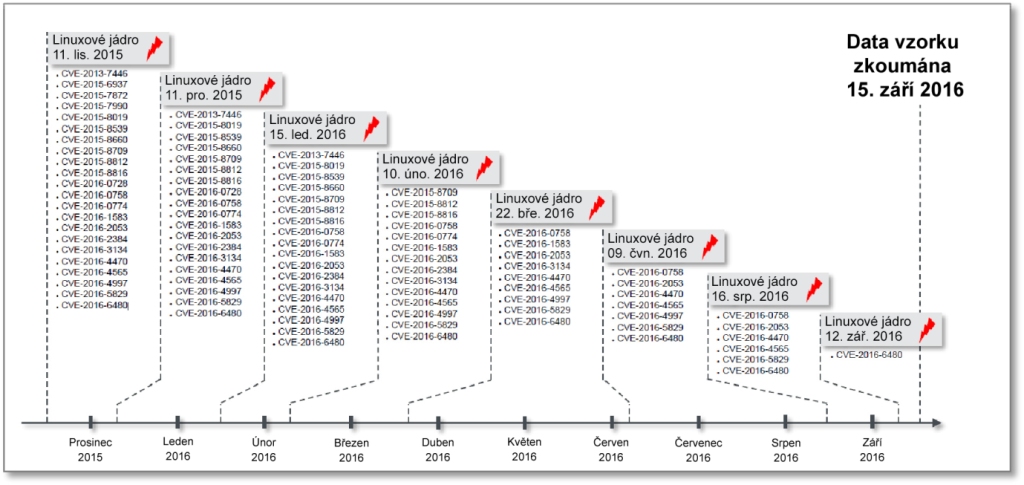
Obrázok 1: Histórie aktualizácií jadra pre SUSE Linux Enterprise Server 12 SP1 (vydané: 2. mája 2015)
U chýb zabezpečenia s vysokým stupňom závažnosti zvyčajne bezpečnostné tímy „vyvesia červenú vlajku“ a urobia všetko pre to, aby hrozbu eliminovali čo najskôr. Problém je v tom, že ak sa útočníkovi podarí nájsť slabinu v linuxovom jadre, môžu mať lokálne bezpečnostné opatrenia (napríklad SELinux, AppArmor, ACL, čiže rozšírené zoznamy prístupových práv a firewally) len obmedzenú účinnosť alebo nemusia fungovať vôbec. Všetky aplikácie, ktoré na danom systéme bežia, budú tiež dotknuté za predpokladu, že ich dáta sú používané lokálne (napríklad v zozname použiteľných automaticky mountovaných systémov „automounter“ v súbore /etc/mount.map).
K oznamovaniu bezpečnostných chýb nedochádza systematicky a v balíčkoch. Skôr je tendencia oznamovať ich ihneď, akonáhle je každá z nich objavená alebo opravená. Ak by ste chceli zaručiť maximálnu bezpečnosť, museli by ste neustále svoj systém reštartovať a vyrovnať sa s opakovanými odstávkami. Na druhej strane – keď bezpečnostné chyby opravovať nebudete, vystavujete svoj systém a firmu obrovským rizikám, za ktoré môžete byť osobne zodpovední. Práve preto IT správcovia potrebujú spôsob, ako linuxové jadro zaplátať bez nutnosti neustále zatvárať aplikácie a reštartovať systém.
Čo je „Live patching“?
Live patching, čiže plátanie za chodu je open source technológia, ktorá je súčasťou linuxového jadra od verzie 4.0. Táto technológia umožňuje určité rutiny a zaplátať funkcie linuxového jadra aj keď jadro beží – bez nutnosti systém zastaviť alebo reštartovať. Live patching je založený na projektoch kGraft spoločnosti SUSE a kpatch od Red Hat, ktoré existujú už od roku 2014. Opravou za chodu sa usilujú spoločnosti SUSE a Red Hat o nastolenie štandardnej open source technológie a skombinovanie výhod kGraft a kpatch. V súčasnosti live patchingu chýba len model zachovania konzistentnosti, ktorý by zaručil jednotné uplatnenie záplat v systéme. Prístupy nástrojov kGraft a kpatch sú rôzne a vývojári sa ešte len musia definitívne zhodnúť, ako by v tomto ohľade malo plátanie za chodu fungovať.
Vysvetliť, ako „live patching“ linuxového jadra funguje, je ľahké: najprv je nutné dať každej funkcii linuxového jadra päťbytovú hlavičku. To sa vykonáva pri kompilácii linuxového jadra – teda na strane distribútora. Táto päťbytová hlavička je zvyčajne prázdna. Pri prevádzke sa jednoducho obchádza a preto nemá na výkon systému žiadny vplyv. Ak však bude potrebné funkciu linuxového jadra kvôli bezpečnostnej chybe opraviť, hlavička príslušné funkcie sa počas “živej aktualizácie“ zmení a do pamäte sa načíta revidovaná verzia danej funkcie. Live patching využíva rámce ftrace pre presmerovanie toku vykonávaných inštrukcií na novú opravenú funkciu („call redirection“).
Nasledujúci obrázok znázorňuje značne zjednodušený príklad procesu plátania:

Obrázok 2: Zjednodušená schéma procesu plátania
Existujú však ďalšie možné scenáre, kde v tejto forme plátanie nutne zlyhá, alebo u ktorých vyústi v nekonzistentné výsledky.
Pri kompilácii linuxového jadra sa používa tzv. „function inlining“, ak sa kompilátor napríklad kvôli výkonu rozhodne kopírovať funkciu do už načítanej funkcie, namiesto aby použil „call“. Týmto spôsobom sa chybná funkcia môže v linuxovom jadre vyskytnúť mnohonásobne. Pri plátaní preto musí byť použitá informácia DWARF, aby došlo k „odchyteniu“ všetkých kópií danej funkcie.
Problémy tiež môžu spôsobiť statické symboly v linuxovom jadre, najmä ak nie sú korektne exportované alebo sú nastavované funkciou, ktorá má byť plátaná. Linuxové jadro má našťastie zoznam všetkých symbolov – a ten je možné pri záplate pre tento prípad využiť.
Globálne optimalizácie GCC, ako napríklad „-O2“, umožňujú linuxovému jadru dosiahnuť významný nárast výkonu a aktivovať možnosti optimalizácie, napríklad „-fip-sra“. Táto voľba riadi medziprocedurálnu skalárnu náhradu agregátov a odstránenie nepoužitých parametrov funkcie. V dôsledku toho dochádza k trom problémom.
Funkcia IPA-SRA umožňuje:
- Nahradiť príkaz CALL na konci funkcie príkazom JMP, pokiaľ je CALL posledným stavom danej funkcie.
- Konvertovať parametre, ktoré boli spracované, na odkazy na hodnoty týchto parametrov za predpokladu, že nedošlo ku zmene ich hodnôt.
- Existenciu funkcií jadra v rôznych variáciách, z ktorých niektoré majú málo parametrov, pokiaľ nemajú žiadny vplyv na výkonnosť behu danej funkcie.
Vo všetkých týchto prípadoch ponúka pomoc výpis optimalizácií pomocou nástroju gcc.
Spomínaný model udržania konzistentnosti je pre live patching najväčším orieškom, pretože málokedy je potreba zaplátať iba jednu funkciu. U bezpečnostných chýb linuxového jadra je bežnejšie, že sa vyskytnú súbehy nepriaznivých interakcií medzi viacerými funkciami linuxového jadra súčasne. Ako to dopadne, keď je potreba prenastaviť celý rad parametrov danej funkcie a tento krok ovplyvňuje všetky načítané funkcie? Podobne problematické sú akékoľvek zmeny výstupných parametrov, ktoré sa majú použiť vo všetkých nasledujúcich funkciách. V prípade sémantických zmien danej funkcie je preto veľmi pravdepodobné, že úpravy bude potrebné vykonať aj u ostatných funkcií linuxového jadra.
Plátanie viacerých funkcií vyžaduje vhodný model zachovania konzistentnosti. A tu sa nástroje kGraft a kpatch od seba líšia. Kým kGraft dáva prednosť „lenivej migrácii“, ktorá ho pre uplatnenie záplaty na jadro nepotrebuje zastaviť, kpatch používa „bezpečnosť aktivít“, ktorá na krátku dobu jadro zastaví a vykoná proces záplaty. Oba prístupy majú svoje silné i slabé stránky. Vývojári konceptu plátania za chodu môžu prijať jeden z nich alebo vyvinúť úplne nový model.
Live Patching – užitočné obohatenie každého dátového centra?
Ostala len otázka, aké užitočné môžu byť živé aktualizácie linuxového jadra v praxi. Treba povedať, že v prípade častých plánovaných odstávok tento problém nie je nutné riešiť vôbec. Počítačové systémy Haleovho teleskopu na Mount Palomar sú toho trochu exotickým dôkazom. Možno ich bez problémov aktualizovať každý deň, pretože kým svieti Slnko, teleskop aj tak nič nevidí, a preto nemusí byť funkčný. Znamená to, že každý deň je k dispozícii niekoľko hodín na údržbu, kedy je možné inštalovať záplaty.
Inak je to v prípade, ak je na údržbu vyhradené len krátke časové okno. Systémy, ktorých výkon je využitý celý týždeň a bežia na nich simulácie, nie je ľahké zastaviť a reštartovať bez toho, aby sa simulácie prerušili. Ak máte prostredie so stovkami alebo tisíckami virtuálnych počítačov, ktoré naliehavo potrebujú záplaty, stojí to veľké peniaze. U aplikácií bežiacich v operačnej pamäti, ako SAP HANA, môže ľahko inicializácia hardvéru a verifikácia inštalovanej pamäte s kapacitou 12 TB trvať 30 minút. Po spustení operačného systému je nutné následne načítať oných skoro 12 TB z pevného disku do operačnej pamäte. Pri predpokladanej rýchlosti prenosu dát 500 MB/s to môže trvať asi sedem hodín. Pre obyčajnú inštaláciu záplat jadra nie sú takto dlhé odstávky akceptovateľné.
Ak chcete využiť výhody live patchingu, môžete si teraz vybrať kGraft od spoločnosti SUSE alebo kpatch od Red Hat. V tejto chvíli nemožno povedať, či sa títo dvaja distribútori na prijatí záplat za behu dohodnú, ani kedy by k tomu mohlo dôjsť.


