Aké bude zajtra počasie? Zhasni svetlo! Kúp mi lístky do kina! Smart asistenti sú tu, avšak ich cesta sa ešte len začína. Hlasové technológie budú totiž celkom kľúčovým vstupným aj výstupným rozhraním počítačov budúcnosti, ktoré zatieni úplne všetko.
Aj keď je hlas prioritným komunikačným prostriedkom ľudí, na ktorý si spoločne s mimikou a inými vizuálnymi signálmi zvykáme už od narodenia, v rámci komunikácie s počítačmi sa drží stále značne v pozadí. Prednosť dostávajú dlhodobo „ručné“ periférie v podobe dotykového displeja či fyzickej klávesnice a myši.
Tento stav však nemôže trvať večne. Presuňte sa vo svojej fantázii napríklad o 100 rokov do budúcnosti a predstavte si, že máte pred sebou pokročilého robota s ľudskou postavou, ktorý vám vypomáha v domácnosti. Ako s ním komunikujete? Určite nie tak, že prídete k nemu a naťukáte do jeho chrbta príkazy na dotykovej klávesnici a takisto určite jeho chôdzu neovládate tak, že hýbete joystickom položeným na stole. Je celkom jasné, že takýto robot musí reagovať bezchybne na hlasové príkazy a hlasom s vami musí aj komunikovať.
Vývoj rozpoznávania reči trvá už mnoho desaťročí, pričom jedným z prvých zariadení tohto typu bol stroj IBM Shoebox (doslova škatuľa na topánky), ktorý bol predstavený na Svetovej výstave v roku 1961. Rozpoznával 16 slov a 10 čísiel, podľa ktorých dokázal po vyslovení zasvietiť konkrétnu žiarovku na svojom tele. Aj keď sa v nasledujúcich dekádach schopnosti hardvéru a softvéru rozširovali a počet možných slov narastal na tisíce, obrovská variabilita reči nielen v rámci rôznych ľudí, ale aj toho istého človeka, nikdy neumožnila plnohodnotné presadenie, pretože chybovosť bola skrátka enormná.
Situácia sa však v druhej dekáde 21. storočia začala veľmi rýchlo meniť. Dôvodom je nástup hlbokých neurónových sietí a iných pokročilých prvkov umelej inteligencie, vďaka ktorým sme za posledných 6 rokov vykonali väčšie skoky, než za predchádzajúce 4 desaťročia.
Raketový nárast používania v posledných rokoch
Obrovské pokroky vo vývoji rozpoznávania reči viedli v rokoch 2011 až 2013 k prvej generácii masovo rozšírených, hlasom ovládaných služieb a produktov. Šlo predovšetkým o hlasových asistentov, pričom na trh vletela najprv Siri od Applu, nasledovaná systémom Now od Googlu, S Voice od Samsungu a mnohými ďalšími. Aj keď vďaka vtedajšiemu stavu vývoja šlo o masívny rozdiel oproti predchádzajúcim systémom, marketingové oddelenia Applu a iných firiem to prehnali so superlatívmi a spôsobili úvodné rozčarovanie, s ktorým budeme musieť ešte niekoľko rokov tvrdo bojovať. To všetko aj napriek tomu, že systémy sú dnes už na celkom inej úrovni.
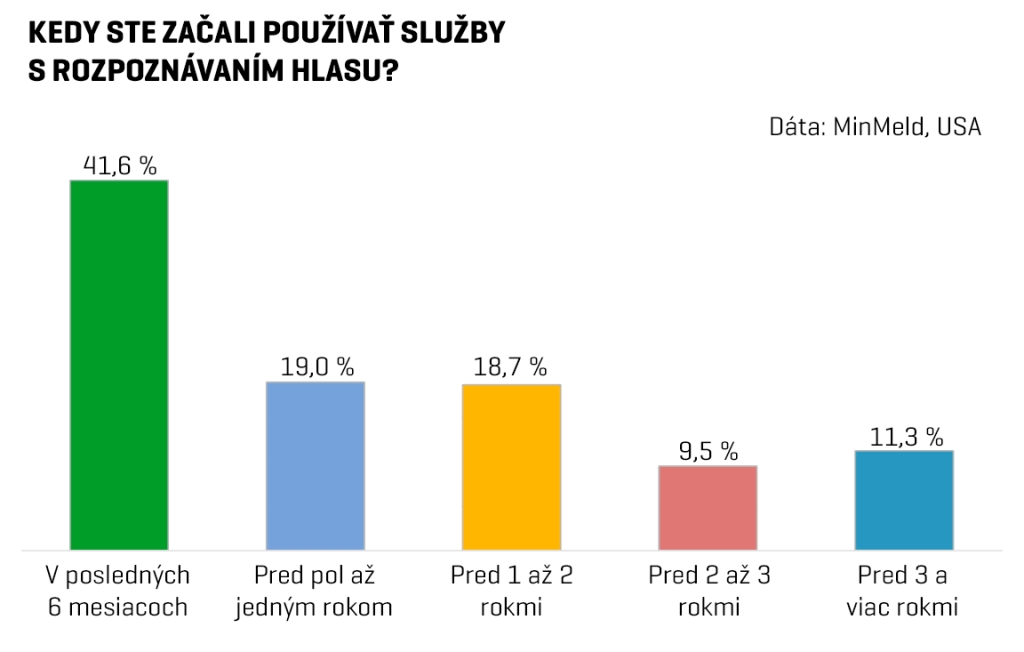
Ľudia si každopádne pokles chybovosti začínajú podvedome všímať, čo je vidieť na rapídnom náraste používania hlasového vyhľadávania po roku 2013. Google v minulom roku oznámil, že počet hlasových zadaní vyhľadávania na smartfónoch s Androidom začal prekračovať 20 %. Nemenej zaujímavý je aj výsledok minuloročnej ankety spoločnosti MinMeld zo San Francisca, v ktorej sa firma opýtala ľudí používajúcich hlasové vyhľadávanie, kedy toto rozhranie začali používať. Až 42 % z nich sa vyjadrilo, že len v posledných šiestich mesiacoch. Kým v prípade západnej populácie a Googlu sa za posledných šesť rokov zvýšil počet vyhľadávaní hlasom sedemnásobne, ešte väčší skok sa odohral na čínskom trhu, kde lokálny vyhľadávací gigant Baidu reportuje viac ako 26-násobný nárast od roku 2014.
Odpovedať, prečo sa tak deje je pomerne jednoduché. Začíname sa totiž veľmi tesne blížiť k zlomovej hranici. Na prvý pohľad sa môže zdať, že napríklad pokrok z 95 % úspešnosti rozpoznania na 98 % je nevýznamný, avšak v skutočnosti ide o prechod medzi tým, či takúto funkciu budete používať len občas alebo vôbec, alebo naopak skoro neustále. Žiadaným stavom je, aby človek nad chybovosťou prestal vôbec uvažovať. Dnes napríklad vôbec nepremýšľame nad tým, či softvérová alebo fyzická klávesnica píše iné písmená, než na nej chceme naťukať. Preklepy síce robíme, ale rýchlo ich opravujeme a ani sa nad tým nepozastavujeme. Naša chybovosť je totiž nad hranicou netolerantnosti.
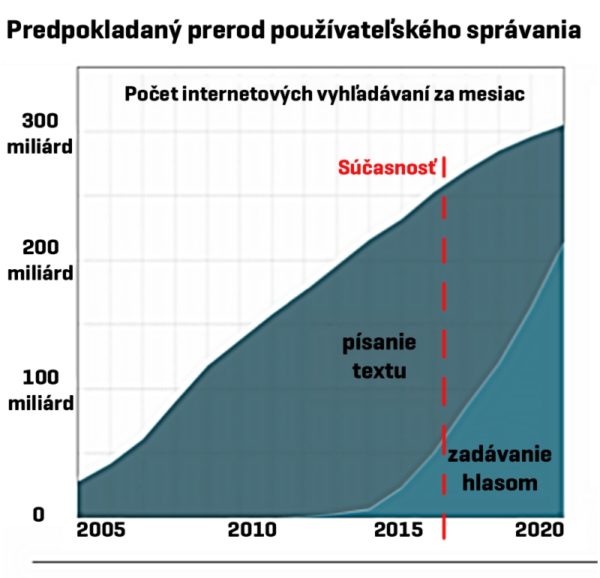
Optimizmus v súvislosti s aktuálnym veľkým nárastom majú aj vývojári. V súčasnosti mnoho odhadov počíta s tým, že do roku 2020 by hlasové zadávanie výrazov do internetových vyhľadávačov mohlo tvoriť až dve tretiny všetkých mobilných hľadaní. Nie je pri tom tajomstvom, že sa počíta s tým, že mnohé zariadenia inak ako hlasom ani ovládané nebudú, čo sa týka predovšetkým zariadení v oblasti Internetu vecí (IoT).
Hlasové rozpoznávanie v súčasných produktoch
Rozpoznávanie hlasu je integrované v smartfónoch so systémom Android aj iOS, pričom dostupné je vo veľkej miere aj vo Windows 10 prostredníctvom Cortany. V prípade Windows si však Cortanu užijú len používatelia anglickej verzie systému. Aj keď používanie hlasového zadávania textu do vyhľadávacieho políčka medzi používateľmi rýchlo stúpa, stále je z hľadiska celkového objemu pomerne málo rozšírené. Jedným z bežných dôvodov je „historická zatrpknutosť“. Bežný človek sa o ňom v minulosti dopočul a vyskúšal ho, pričom zistil, že to príliš dobre nefunguje a keďže používanie bolo poriadne otravné, tak mu dal navždy zbohom. Mnoho ľudí ale takéto zbohom dalo pred tromi či piatimi rokmi a neuvedomujú si, aký obrovský pokrok tieto systémy robia v poslednej dobe.
Súčasná úspešnosť rôznych zabehnutých systémov je zhruba na úrovni 94 %, pričom naďalej stúpa, pretože sú do nich neustále integrované nové riešenia a postupy z nových neurónových sietí. Používanie hlasu pri klasickom internetovom vyhľadávaní vám pritom zadávanie výrazov niekoľkonásobne zrýchli už dnes. Stačí ťuknúť na malú ikonku mikrofónu vo vyhľadávacom políčku a hovoriť. Netreba si robiť ilúzie o tom, že by ste napríklad výraz „Arnold Schwarzenegger filmografia“ zadali na klávesnici rýchlejšie, nech už ste akýkoľvek rýchly pisár.
V lete minulého roku uverejnila Stanfordova univerzita pekné video k svojej štúdii o aktuálnych schopnostiach rozpoznávania reči, v ktorom proti sebe postavila rýchlych pisárov na dotykovej a fyzickej klávesnici a človeka, ktorý namiesto písania použil existujúce riešenia rozpoznávania reči. Následne im zobrazovali vety a merali čas ich zadania. Zatiaľ čo človek používajúci hlasové rozhranie ich skrátka len rýchlo prečítal, ostatní ich museli písať, čo im trvalo v priemere trojnásobne dlhšiu dobu.
Je samozrejme pravda, že výsledky týchto systémov sú v súčasnosti najlepšie v angličtine, tesne nasledované čínštinou, avšak slovenčina je dnes už takisto plne použiteľná, a to najmä pri strohom a jednoduchom zadávaní, aké sa používa pri internetovom vyhľadávaní. Na Androide aj iOS je možné takisto zadávať text hlasom v akomkoľvek programe. Stačí kliknúť na ikonu mikrofónu na softvérovej klávesnici (na niektorých zariadeniach pozíciu mikrofónu zaberá ikona nastavenia a jej podržaním je nutné ju zameniť). Vyťahovanie telefónu z vrecka, ťukania na aplikáciu či na ikonu mikrofónu však nie je nič pohodlné. Prečo svoje otázky a požiadavky nehovoriť rovno do vetra vtedy, keď ich máte?
Asi nič nedemonštruje ostré vsadenie na koncept rozpoznávania reči viac, než moderná podoba domácich inteligentných asistentov v podobe Amazon Echo či Google Home. Tie totiž displej vôbec neobsahujú. I keď štart predajov týchto zariadení je pozvoľný, nedá sa povedať, že by nebol záujem.
Kým v roku 2015 predal Amazon 2,4 milióna kusov, tak v roku 2016 to už bol viac ako dvojnásobok (5,2 milióna). Prítomnosť takmer 8 miliónov „Alexa valčekov“ v domácnostiach (predovšetkým amerických) je nepochybne zaujímavá. Zariadenie vám odpovie na otázky s pomocou vyhľadávača a bez problémov vám oznámi, aká hora je najvyššia, aký deň týždňa pripadá na 28. 9. 2042, ako ďaleko je od vás nejaká adresa a za ako dlho sa tam dostanete a podobne. Môžete mu zadať prehrávanie hudby, požiadať ho o vtip či ho nechať objednať nejaký produkt.
V novembri minulého roku predstavil Google svoj ekvivalent, nazvaný Home, pričom sa postupne objavujú aj rôzne varianty od iných výrobcov. V Číne napríklad LingLong predstavil zariadenie DingDong a na výstave CES sme mohli vidieť natiahnutie tohto konceptu na asistenčných robotov, ako je napríklad Airport Guide Robot od LG pre pomoc na letisku, alebo roztomilého robotíka Kuriho, ktorý sa ako akási kombinácia Amazon Echo a R2-D2 zo Star Wars začne predávať toto leto a videli sme ho na tlačovke firmy Bosh.
To, prečo sú tieto zariadenia už pozitívnejšie prijímané, nemá svoj pôvod len v pokroku v rámci zníženia chybovosti, ale aj v citlivejšom marketingu. Keď v roku 2011 predstavoval Apple svoju Siri, tak v rámci marketingového ošiaľu všetkým sľúbil, že budú so svojím telefónom môcť komunikovať ako s inou osobou. V tej dobe síce neurónové siete už poskytovali výrazné zlepšenie oproti starým riešeniam, avšak v roku 2011 ešte ani zďaleka nemohli doručiť to, čo Apple pyšne propagoval. Výsledkom bol veľmi zlý prvý dojem, čo z technológie spravilo terč posmechu.
Vtipné scénky s nezmyselnými akciami sa dostali do skečov, filmov aj bežnej konverzácie a ľudia sa smiali, keď údajne inteligentný asistent na otázku „Siri, čo znamenajú skratky AC a DC“, začal napríklad prehrávať hudbu od AC/DC. Amazon bol na konci roku 2014 pri uvádzaní zariadenia Echo naopak omnoho triezvejší a predvádzal ho ako smart reproduktor, ktorý dokáže odpovedať na pár príkazov. Ľudia tak neočakávali veľa a boli príjemne prekvapení, a to najmä preto, že schopnosti zariadenia sa za nasledujúce dva roky výrazne posunuli a priestor je už aj na odvážnejší marketing. K situácii prispieva pravdaže aj to, že do zariadenia tohto typu sa dokážu vtesnať výrazne lepšie mikrofóny.
Potenciál týchto riešení je obrovský. Akonáhle si raz ľudia zvyknú na to, že môžu klásť svoje otázky alebo požiadavky len tak do vetra a dostávať na ne odpoveď alebo odozvu spoľahlivo, nikdy sa už nebudú chcieť vrátiť späť. Hlavne v domácnosti sa pri tom nemusíte zaoberať tým, že vás bude počuť vaše okolie. Ak cestujete autobusom, tak nemáte záujem, aby všetci okolo vedeli, čo zadávate do vyhľadávača. Ak ste ale doma a zahlásite, že chcete pridať 2 °C na vykurovaní, pustiť hudbu, zhasnúť svetlo a daná vec sa naozaj stane, ide o veľmi návykovú vec. Tieto veci sa pri tom stále rozširujú na viac prvkov internetu vecí. Koncom januára napríklad Google oznámil, že do svojho zariadenia Home integroval ovládanie IoT od spoločností Belkin (Wemo) a Honeywell, ktoré sa pridali k už podporovanému zoznamu spoločností v podobe Samsungu (SmartThings), Philipsu (Hue) a takisto pravdaže Nestu, ktorý pod krídla Alfabetu patrí.
Ovládanie prvkov domu, objednávanie jedla či produktov, zápisy do kalendára alebo odpovedanie na otázky je v rámci týchto zariadení pocitovo dosť odlišná činnosť. Po prvý raz totiž môžete prestať mať pocit, že počítač alebo inú elektroniku priamo používate, alebo ovládate. Ak sa opýtate rodinného príslušníka, či nevidel vaše kľúče a on vám odpovie, že sú zasunuté stále vo dverách, nemáte pocit, že ho ovládate. Ide o skutočnú interakciu. A práve tieto dvere zariadenia s prirodzeným a neustále dostupným hlasovým ovládaním otvárajú. Tento pocit nikdy nebudete mať v prípade zariadenia, ktoré na hlas reaguje až po vytiahnutí z vrecka a stlačení tlačidla.
Nie je hlas ako hlas
Rozpoznávanie hlasu je v základe konverziou zvukového signálu na sekvenciu slov. Úlohou systému je aby „počul“, „pochopil“ a takisto správne reagoval na danú zvukovú informáciu. Týmito úlohami sa softvéroví inžinieri zaoberajú už od 50. rokov minulého storočia, pričom sa rýchlo ukázalo, o akú veľmi náročnú úlohu ide. V počiatkoch bol veľký problém hlas vôbec digitalizovať, pretože hardvérový výkon počítačov skrátka nebol dostatočný. Prvé systémy, ktoré s hlasom dokázali ako-tak pracovať, prišli v 80. rokoch, pričom ich schopnosti boli pravdaže vskutku rudimentárne.
Amazon Echo
Rozpoznávanie reči má premenlivú zložitosť, ktorá na prvý pohľad nie je zrejmá. Väčšine ľudí rýchlo dôjde, že rozpoznávanie jedného alebo niekoľkých nadväzujúcich slov (napríklad zadanie vyhľadávacieho výrazu do Googlu) je značne jednoduchšia úloha, ako rozpoznávanie dlhších komplexných viet.
Komunikácia so súčasným asistentom, ako je napríklad Amazon Echo, Apple Siri či Microsoft Cortana, patrí v skutočnosti k tým najľahším. Predpokladá sa pri nich totiž, že rozpráva len jeden človek, oslovuje priamo prístroj a zadáva mu konkrétnu úlohu v rámci systémov, ktorých zoznam je známy. Ide teda napríklad o otázku „kto je slovenský prezident“, ktorej odpoveď vypracuje vyhľadávač a inteligentný asistent po zadaní výsledok prakticky len prečíta. Môže ísť aj o komplexnejšie zadanie úlohy, ako napríklad „Zruš moju schôdzku o dvanástej. Pošli SMS Karolovi. Nestihnem to, stojím v zápche. Odošli.“, čo asistent vykoná v rámci programu kalendára, zoznamu kontaktov a aplikácie na posielanie správ. Operuje totiž v známom prostredí a má základnú „predstavu“ o tom, čo používateľ zadáva (otázka/úloha). Ak sa rozpoznanie nepodarí, systém môže dokonca položiť otázku a požiadať o zopakovanie či spresnenie.
V prípade kontinuálneho prepisu záznamu, ako napríklad zo zaznamenaného zvuku prednášky či prehrávaného filmu, to pravdaže nejde. Aj tu je však zložitosť variabilná. Najjednoduchšia podoba, v ktorej sú systémy na rozpoznávanie reči dnes už značne dobré a majú len veľmi malú chybovosť, je hlas s dobrou artikuláciou, uceleným prejavom a správnou vetnou skladbou. Je to prípad, pri ktorom systém rozpoznáva napríklad osobu, ktorá nahlas číta text článku alebo knihy, prípadne reportéra televíznych novín, ktorý číta správu z čítacieho zariadenia.
Google Home
Naopak, veľmi zložitý je bežný hovorový prejav a obzvlášť rozhovor medzi dvoma alebo viacerými osobami. Tu sa totiž vetná skladba rúca a často sa stáva extrémne kostrbatou. Najextrémnejším a najťažším prejavom tohto typu je telefonický rozhovor, pretože osoby nemajú medzi sebou vizuálny kontakt a mimické prejavy sú nahradené zvukovými.
Je zaujímavým faktom, že ľudia si rozdiel medzi rozhovorom a uceleným písaným prejavom bežne neuvedomujú. Máme pocit, že hovoríme celkom „normálne“, súvislo a jasne. Náš mozog je na tieto prejavy už mimoriadne dobre adaptovaný a dokáže ich „zahmliť“ podobne ako fakt, že nevidíme ostro v celom našom zornom poli, ale len v jeho maličkom centre. V prípade zraku sa tento fakt stane zrejmý, ak očami zastanete na jednom slove tohto textu a bez pohybu očí skúsite prečítať hocaký text okolo.
Pri hovorenej reči sa tento klam ukáže, ak čítate kompletný textový prepis zaznamenaného telefonického hovoru. Vtedy si uvedomíte, ako často sú ľudia vo vetnej konštrukcii „lajdácki“, vety nezriedkavo kompletne prebudujú za pochodu a podobne. Ak ste niekedy napríklad v novinách čítali prepis telefónneho rozhovoru, v ktorom bol niekto usvedčený zo sprenevery, podvodu a podobne, možno ste dostali pocit, že ide o rozhovor dvoch pacientov psychiatrickej liečebne. V reálnom rozhovore však dané vety pôsobili úplne normálne.
Robot Kuri reaguje na hlasové povely a ovláda IoT domu
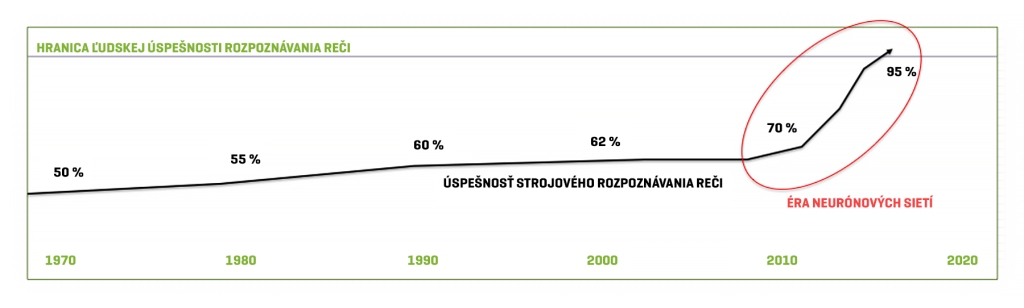
Ak chceme v rámci rozpoznávania reči dobre určiť stav súčasného pokroku, je dobré sa pozrieť na chybovosť práve v tejto najťažšej úlohe. A práve v nej na konci minulého roku dosiahol prelomový výsledok vývojový tím Microsoftu, ktorého pokročilý systém na rozpoznávanie reči sa stal prvým v histórii, ktorý prekonal schopnosti človeka.
Sila rekurentných neurónových sietí
V minulosti rozpoznávanie reči pracovalo s digitálnou zvukovou krivkou nahraného hlasu, ktorá sa rozdelila na niekoľko milisekundové útržky a analyzoval sa ich frekvenčný obsah. Výsledok putoval do akustického modelu, ktorý obsahoval naviazanosti reprezentácií slov, pričom mu pomáhal tzv. Skrytý Markovov model, ktorý vytvoril štruktúry na základe pravdepodobnosti. Tieto dáta boli následne skombinované s inými zdrojmi informácií, pričom šlo hlavne o modely jazyka a výslovnosti a dekodér napokon všetko zosumarizoval a poskytol najpravdepodobnejší výsledok. Vývoj od prvého použitia týchto metód v 70. rokoch minulého storočia bol značne pomalý. Nepomohol ani rýchlo sa zvyšujúci výkon hardvéru, pretože bolo veľmi problematické zistiť, čo spôsobuje tú alebo onú chybu pri detekcii a čo je najväčšou slabinou v konkrétnom rozpoznaní. Takisto nebolo jasné, ako si poradiť účinne s akcentom, horšou výslovnosťou, či hlučnejším prostredím.
Tieto systémy, vyvíjané viac ako 30 rokov, však boli zanechané v histórii v prvej dekáde 21. storočia, keď sa dostali k slovu neurónové siete. Aj s nimi bol však pokrok sprvu len veľmi mierny. Ak sa zameriate na obrázok grafu pokroku týchto systémov v priebehu histórie, môžete si všimnúť, že raketové zlepšovanie začalo až od roku 2010. Katalyzátorom tohto zlepšenia bola významná publikácia nazvaná „Spoločné názory štyroch výskumných skupín“, ktorá vyšla v roku 2009 z pera dvoch významných vývojárov systémov umelej inteligencie. Šlo o Geoffreyho Hintona a jeho tím z Torontskej univerzity a Lia Denga a jeho tímu z Microsoft Research. K nim sa následne pridali do štvorice vývojári z IBM a Google.
Vývoj chybovosti rozpoznávania reči za posledných 50 rokov
V tejto práci vývojári rozobrali obrovský potenciál a nádejné zlepšenie, ktoré prinášajú hlboké neurónové siete, pričom poukázali na to, že najvhodnejší je ich špecifický rekurentný (zvratný) variant, kombinovaný spoločne s ďalšími metódami systémov hlbokého učenia. Vývojári z Microsoft Research to nazvali doslova najväčším prielomom v tomto odbore od roku 1979 a poukázali na potenciál až 30 % zlepšenia. Tieto názory a pohľady boli rýchlo adoptované naprieč celým odvetvím a práve z tohto dôvodu môžeme po roku 2010 vidieť rapídne zlepšovanie rozpoznávania reči a príchod stále nových služieb a produktov, ktoré zlepšujúce sa vlastnosti týchto systémov používajú.
Google zaviedol svoje hlboké neurónové siete do používateľskej prevádzky v rámci Google Voice po prvýkrát v roku 2012, pričom od roku 2013 na systéme začal pracovať aj Geoffrey Hinton, keďže Google odkúpil jeho spoločnosť DNNresearch (Hinton však pokračuje takisto vo svojej akademickej práci na Torontskej univerzite). Systém Googlu patril počas celého obdobia k najlepším na trhu, pričom jeho aktuálne zlepšenie po roku 2015 bolo dosiahnuté špeciálnymi rozšíreniami rekurentných neurónových sietí o Spojovaciu temporálnu klasifikáciu, skrátene CTC (Connectionist Temporal Classification) a rôzne ďalšie techniky. Použité sú v rámci hlasového rozpoznávania Androidu a takisto v príbuzných produktoch, ako napríklad Google Prekladač.
Vývojári Microsoft Research, ktorých neurónová sieť pokorila ľudskú hranicu rozpoznávania reči v októbri minulého roku
Podobne vyspelé systémy Microsoftu sú integrované v asistentke Cortana, hlasovom ovládaní Xboxu a takisto v automatickom hlasovom prekladači, ktorý je integrovaný do programu Skype. Systémy Googlu a Microsoftu v rokoch 2015 až 2016 postúpili z 92 % úspešnosti medzi 94 a 95 % úspešnosť pri klasických úlohách. V tesnom závese sú však aj tímy ostatných spoločností, ktoré rozhodne nelenia. Amazon svoj „tím Alexa“ v priebehu minulého roku rozšíril o stovky nových vývojárov, ktorí sa zapoja do vývoja zariadenia Echo a veľké pokroky urobil aj čínsky internetový gigant Baidu so svojím systémom Deep Speech 2. Jeho vývojový tím vedie významný vývojár Andrew Ng Yan-tak, profesor Stanfordovej univerzity, ktorý má pod palcom vývojársku odnož Baidu sídliacu v Silicon Valley.
Mierne sa začína v tejto sfére prebúdzať aj Apple, ktorý v minulom roku kúpil za 200 miliónov dolárov americkú spoločnosť Turi z oblasti strojového učenia a umelej inteligencie a takisto za nezverejnenú sumu aj indickú spoločnosť Tuplejump s rovnakým zameraním. Apple je vo vývoji umelej inteligencie v pozadí, pričom firma mala dlhú dobu problém prilákať akékoľvek významné vývojárske mená z tejto oblasti. Dôvodom je hlavne uzavretosť spoločnosti, ktorá nepovažuje za dôležité publikovať vedecké práce v rámci akademickej sféry. V minulom roku však v súvislosti s umelou inteligenciou došlo k prehodnoteniu tohto postoja a firma oznámila ukončenie týchto obmedzení, v snahe nalákať viac talentov. Prvá vedecká publikácia sa objavila v decembri, v súvislosti s rozpoznávaním obrazovej informácie. Bola publikovaná prostredníctvom Cornellovej univerzity a jej autorom bol Ashish Shrivastava a jeho tím.
Dva obrovské vývojové pokroky v minulom roku
V priebehu roku 2016sa najväčšie prielomy
v oblasti reči a umelej inteligencie udiali vo vývojárskych oddeleniach Googlu a Microsoftu. Oba vývojové tímy dosiahli pri tom veľký pokrok v riešení dvoch odlišných typov problémov. V septembri publikoval Google výsledky svojho nového generatívneho modelu zvukových vlnových kriviek, nazvaného WaveNet. V tomto prípade nejde o pokrok v rozpoznávaní reči, ale v jej tvorbe, teda syntéze, čo je veľmi dôležité v prípade asistentov, ktorí s nami komunikujú.
Schéma práce konvolučnej neurónovej siete WaveNet
Dominantným riešením umelého rozprávania, respektíve softvérového čítania textu je dlhodobo tzv. konkatenačná syntéza, ktorú dobre poznáte vďaka veľmi silnému „robotickému prejavu“ (napríklad v syntetizátore reči Stephena Hawkinga). Pri tejto metóde sa používa obrovská databáza nahratých krátkych úsekov reči v podobe slabík, písmen a iných krátkych štruktúr, ktoré sú následne softvérom kombinované do slov a viet. Výsledkom je, že je prakticky nemožné zmeniť výrazne hlas na inú osobu bez toho, aby ste nenahrali novú databázu zvukov a rovnako nie je možné ani operovať s dôrazom či emóciami v reči. Zlepšením v tomto smere bola tzv. parametrická syntéza, pri ktorej sú zvukové dáta uložené ako parametre zvukového modelu, ktorý je možné následne kontrolovať. Toto riešenie dosahuje niekedy lepšie, inokedy horšie výsledky ako klasický prístup. Prekvapivo je obvykle výsledok lepší v čínštine, než v angličtine.
Google zvolil celkom nový prístup s použitím konvolučnej neurónovej siete (používajú sa hlavne v súvislosti s obrazovou informáciou), pomocou ktorej generuje jednotlivú zvukovú krivku do prirodzenejšej podoby. Neurónová sieť počúvala pri výučbe reč bežných ľudí, podľa čoho si sama vytvorila kostru toho, ako má reč vyzerať a akými pravidlami sa riadi a následne podľa toho generovala jednotlivé slová z dostupných vzoriek. Rozdiel oproti stávajúcim riešeniam je masívny, pričom je ho pravdaže nutné počuť na vlastné uši.
Klasická parametrická syntéza:
Klasická konkatenačná syntéza:
Syntéza pomocou hlbokej neurónovej siete WaveNet:
Generovaná reč pripomína reálnu osobu skutočne výrazne, pričom robotický prejav vytvorený skladaním zvukov ustupuje do pozadia (Google udáva zlepšenie o 50 %). Sieť pri tom nemá problémy meniť intonáciu či kompletne zmeniť zafarbenie či identitu hlasu do inej osoby a pohlavia. Zaujímavé je, že systém prejavy reči dobre generuje aj v prípade, že mu zakážete používať známe slová. Pokiaľ viete aspoň trochu po anglicky, je dobré si ukážky vypočuť, pretože ide o zvláštny pocit z toho, že výrazy znejú ako plynulá hovorená angličtina, bez toho aby ste zachytili akékoľvek známe slovo.
Experiment syntézy reči pomocou WaveNet bez použitia slov:
Ukážka zmeny hlasu v rámci syntézy cez WaveNet:
Prevádzka tohto riešenia je v súčasnosti ešte veľmi náročná na výpočtový výkon (je prevádzkovaný na Deepmind systéme Googlu), takže v najbližšej dobe sa nedá očakávať jeho objavenie na bežných zariadeniach, avšak ide o niečo, čo bolo doposiaľ skutočne len snom a existencia týchto riešení je veľmi dôležitá v súvislosti s budúcimi zariadeniami.
Druhý nemenej významný pokrok sa v októbri minulého roku udial v laboratóriách Microsoft Research, kde vývojový tím postavil svoj najnovší model neurónovej siete do súboja s telefonickým rozhovorom dvoch osôb. Ako sme už spomenuli, tieto prípady patria k tým vôbec najťažším úlohám pre systémy rozpoznávania reči, pričom Microsoft sa stal prvým v histórii, ktorý dosiahol výsledky rozpoznávania reči na úrovni človeka.
Použil v tejto sfére dobre známe zvukové súpravy (Switchboard a CallHome), ktoré tímy z oblasti umelej inteligencie používajú už dlhšiu dobu a je teda možné dobre porovnávať pokroky systémov v jednotlivých rokoch. Aby tím overil, aký je výkon človeka pri nich naozaj, vložil ich do pracovného zadania profesionálnych prepisovateľov, bez toho, aby tušili, že ide o niečo špecifické (profesionálny prepis pozostáva z prepisu v reálnom čase a následnej kontroly). Prepisovači k tomu teda pristupovali ako ku akémukoľvek inému záznamu telefonického rozhovoru a hlasovej konverzácie, pričom dosiahli chybovosť 5,9 % v prípade vzorky Switchboard (pracovné a „oficiálnejšie“ rozhovory) a 11,3 % pri vzorke CallHome, čo sú nahrávky hovorov rodinných príslušníkov a blízkych priateľov, ktoré často obsahujú otvorený koniec viet a nedoplňovanie dôležitých skutočností, pretože sú obom stranám známe.
Li Deng je jeden zo svetových lídrov v odbore systémov rozpoznávania reči. Jeho vývojový tím z Microsoft Research v minulom roku po prvý krát navrhol systém, ktorý sa v chybovosti vyrovnal človeku
Vývojový tím Microsoftu použil v rámci rozpoznávacieho systému kombináciu troch rozličných typov konvolučných neurónových sietí a jednu rekurentnú neurónovú sieť typu LSTM (Long short-term memory, teda dlhá krátkodobá pamäť). Sieť bola po tréningu na kognitívnych nástrojoch Microsoftu použitá na rozpoznanie daných zvukových záznamov, pričom dosiahla chybovosť 5,9 % v prípade Switchboard vzorky (totožné s profesionálnymi ľudskými prepisovateľmi) a 11,1 % pri vzorke CallHome (mierne lepšie než ľudský výsledok 11,3 %).
Zaujímavým zistením bolo, že pasáže v ktorých chybovali profesionálni prepisovatelia, boli často v miestach, kde chybovala aj neurónová sieť. Jediná veľká výnimka bola, že neurónová sieť sa na rozdiel od ľudí mýlila v rozlišovaní „pritakávacích“ slov a „prerušovacích“ slov na pozadí. V praxi ide o to, že sa mýli v rozlíšení toho, keď na pozadí hovoríme „uhm-uhm“, čím dávame človeku najavo, že rozumieme, čo sa nám snaží povedať a chceme, aby pokračoval a medzi prejavom „eeehm“, ktorým sa ho snažíme zaraziť a chceme prevziať slovo, aby sme povedali nejakú pripomienku.
Prekvapivé takisto bolo, že aj keď počet chýb ľudí a neurónovej siete bol zhruba rovnaký, ľudia ich urobili vo väčšej miere tak, že nejaké slovo pri prepise vynechali, zatiaľ čo neurónová sieť urobila chybu tým, že doplnila nejaké podobné nesprávne. Je to zrejme z dôvodu, že človek pri neistote volí radšej vynechanie údaju, ako jeho nesprávne zadanie. Túto vlastnosť neurónová sieť nemá, pretože skrátka považuje za správne slovo to, ktoré má najvyšší stupeň pravdepodobnosti správnosti. Každopádne ide o úžasný výsledok a Microsoft zrejme v blízkej dobe bude chcieť použiť tento typ siete aj vo svojich produktoch, čo povedie k ďalšiemu zlepšeniu.
Rozpoznávanie hlasu ako kľúčová technológia 21. storočia
Aj keď je rozpoznávanie hlasu už šesť desaťročí vyvíjaná technológia, až v súčasnosti, keď začína dosahovať paritu s človekom, začína svoju cestu naozaj. Rozpoznanie toho, čo hovoríme a čo tým myslíme, sú síce dve rozdielne veci, avšak oba problémy sú so sebou úzko späté a bez seba nemôžu existovať. Hlasové ovládanie, či lepšie povedané hlasová interakcia, je ďalším stupňom používateľských rozhraní počítačov. Podobne ako sme sa v minulosti presúvali z textovej éry systémov typu DOS ku grafickým rozhraniam a neskôr zas napríklad k dotykovému ovládaniu, dnes sa začíname posúvať smerom k hlasovej ére.
Mnoho ľudí má pocit, že sa tak určite nestane, podobne ako v minulosti si mnohí ľudia boli istí, že dotykové displeje sa nemôžu presadiť, pretože ľudia si nechcú mastnými prstami ťukať na miesto kam sa neustále pozerajú. Doba sa však mení. Hlasové ovládanie je nevyhnutné pre technológie blízkej budúcnosti v rámci IoT a príbuzných riešení inteligentnej domácnosti.
Cortana na anglických Windows 10
Tak ako dotykové displeje nevyhubili fyzické klávesnice a myši úplne, pretože nie vždy sú najvhodnejšie, tak ani hlasové zadávanie nevyhubí písané zadávanie textu. Písanie totiž bude mať stále význam napríklad v súvislosti so súkromným zadávaním informácie a s komponovaním zložitejších textov pomalším tempom. Ak však ale sedíte s vaším priateľom v autobuse vedľa seba, nekomunikujete vzájomne písaním na smartfónoch, ale rečou. Nie je pri tom dôvod, aby ste to nerobili aj s vašimi zariadeniami v rámci domácnosti, či v mnohých prípadoch aj vonku medzi ľuďmi.
Všetko pri tom závisí len od spoľahlivosti, pretože už teraz vieme, že hlasová komunikácia je pohodlnejšia. Ak si ľahnete do postele a zahlásite „Alexa, zhasni svetlo a nastav mi budík na ôsmu ráno“, tak pokiaľ vám niečo nebude čítať myšlienky, neexistuje už ľahšia a pohodlnejšia cesta. V súčasnosti sa v bežne dostupných zariadeniach blížime k hranici rozpoznávania na úrovni človeka a systémy vo vývoji už dokonca túto hranicu aj mierne prekračujú. Akonáhle je technológia v tomto stave, jej okovy sa rúcajú. A ľudia málokedy dávajú prednosť veciam, ktoré sú menej pohodlné a zdĺhavejšie.
Britský genetik John Haldane má pekný citát o tom, že veci ktoré sú časom prijaté ako samozrejmé prechádzajú štyrmi štádiami. Prvým štádiom je, že vec je označená za bezcenný nezmysel. Druhým štádiom je jej označenie za zaujímavé, ale zvrhlé riešenie, zatiaľ čo v tom treťom sa z nej stane trochu užitočná, ale inak nedôležitá vec. Napokon nasleduje posledné štádium, keď je vec prijatá ako samozrejmosť a nikto si už bez nej nedokáže predstaviť život. Dnes sa podľa názorov mnohých bežných používateľov presúvame z druhého štádia do toho tretieho. Vzhľadom na budúce zariadenia je ale nevyhnutné, že rozpoznávanie hlasu a jeho integrácia do rozhraní počítačov a elektroniky sa skončí v tom štvrtom.
Tento článok vyšiel aj v tlačenom januárovo-februárovom vydaní TOUCHIT č. 1-2/2017, preto sa niektoré skutočnosti uvedené v článku, môžu odlišovať oproti aktuálnemu dátumu publikovania.