Napohľad strohé biele políčko, občas s obrázkom lupy, definuje internetovú éru viac, než čokoľvek iné. Aj keď sa zdá, že je celkom nemenné, vyhľadávacie mechanizmy pod jeho povrchom ušli od svojich skromných počiatkov obrovský kus cesty. Ich púť sa pritom nekončí. Ako budú vyhľadávače v budúcnosti vyzerať?
Vyhľadávače sú srdcom webu. Bez nich by sme ho veru len ťažko mohli používať tak efektívne a bezstarostne, ako to robíme dnes.
Vyhľadávače sa však postupne menia. Aby pred naše oči prinášali relevantný obsah v stále zväčšujúcej sa pavučine stránok, neprestajne sa prispôsobujú novým technologickým trendom a takisto meniacim sa požiadavkám a očakávaniam používateľov. Súčasný Google, ako reprezentant najpoužívanejšieho moderného webového vyhľadávača na svete, je tak celkom iným kusom technológie než jeho pradedo, ktorý sa s rovnakým názvom objavil v roku 1997.
CEO Googlu Sundar Pichai pri prezentácii integrácie systémov umelej inteligencie
Aj keď je Google na všetkých formátoch počítačov úplným kráľom internetového vyhľadávania, po technologickej stránke má konkurenciu. Nie však početnú. Prakticky jediný vyhľadávač, ktorý sa mu z hľadiska vývojovej pokročilosti približuje, prípadne ho v niektorých špecifických prípadoch aj mierne prekonáva, je Bing od Microsoftu. Jeho pozícia je však trhovo významná len v rámci nemobilného vyhľadávania, teda v rámci notebookov a desktopov, kde má operačný systém Windows dominantný podiel.
Vyhľadávacie mechanizmy Microsoftu majú silnú pozíciu najmä v USA, kde sa starajú až o 34 % vyhľadávacích dotazov (23 % cez Bing, 11 % cez Yahoo, ktoré je na pozadí „Bingom“ obsluhované). Celosvetovo ide o 11 % nemobilného vyhľadávania (7 % cez Bing, 4 % cez Yahoo).
Pozícia Googlu v rámci amerického trhu či skrátka západných krajín je dobre zmapovaná, avšak celosvetové štatistiky v podobe 92 % trhového podielu (96 % v rámci mobilného trhu), ktoré udáva mnoho organizácií, sú často problematické a skreslené. Vietor v číslach spôsobuje tretí a posledný technicky veľmi vyspelý hráč na poli internetového vyhľadávania, ktorým je Baidu.
Ten je prakticky výhradne zastúpený len na čínskom trhu, kde má Google vďaka zákazom minimálny podiel (okolo 1 %). Baidu pritom čínskemu trhu vyhľadávania dominuje, pričom v mobilnej aj nemobilnej sfére sa stará zhuba o 80 % čínskych vyhľadávacích dotazov. Ďalším lokálnym hráčom je napríklad Shenma so zhruba 10 % podielom. Keďže celý svet má momentálne 3,7 miliardy internetových používateľov, z čoho 735 miliónov (20 %) žije v Číne, reálny podiel Googlu tak musí byť zákonite menší ako 80 %.
To je pravdaže stále celkom dominantná pozícia, ktorý sa len tak nezmení. Je veľmi nepravdepodobné, že by v najbližšej dekáde niekto zasiahol do súčasného stavu vyhľadávačov disruptívne. Náklady na ich prevádzku sú masívne a potrebné technologické know-how, nutné pre ich špičkový výkon, je enormné. Na druhú stranu to neznamená, že noví hráči nemôžu preraziť v rámci špecializovaného vyhľadávania, naviazaného na konkrétne služby.
Táto situácia koniec koncov panuje už dnes. Typickým príkladom je napríklad vyhľadávanie ponúk ubytovania, či už v rámci Booking.com, alebo Airbnb, čo je častejší spôsob, ako všeobecné hľadanie a výber ubytovania cez internetový vyhľadávač. Podobne je to aj so sekciou Shop/Nakupovanie, na ktorú sa v rámci vyhľadávačov Google či Bing môžete prekliknúť a hľadať z ponúk produktov.
V USA tomuto druhu vyhľadávania už od roku 2014 dominuje Amazon. Nejde pri tom len o hľadanie už vybratého produktu. Ide aj o vyhľadávanie v rámci procesu rozhodovania, pozostávajúce z prvotného výberu, posudzovania parametrov, čítania recenzií profesionálnych redakcií a názorov používateľov, ktoré sú vykonané iba preklikmi cez Amazon, bez účasti internetového vyhľadávača.
Podľa aktuálnych štatistík, ako je napríklad trhový prieskum investičnej firmy Raymond James Financial, už v súčasnosti tento spôsob preferuje 52 % amerických používateľov internetu. To je pomerne rýchly nárast od 47 % v minulom roku a 38 % v roku 2015. U nás čiastočne podobná situácia nastáva s portálmi, ako je napríklad Heuréka, ktorá je často prvotným cieľom vyhľadávania produktov, namiesto regulárneho vyhľadávača. Budúcnosť klasických vyhľadávačov tak bude nepochybne tvarovaná aj týmito vplyvmi.
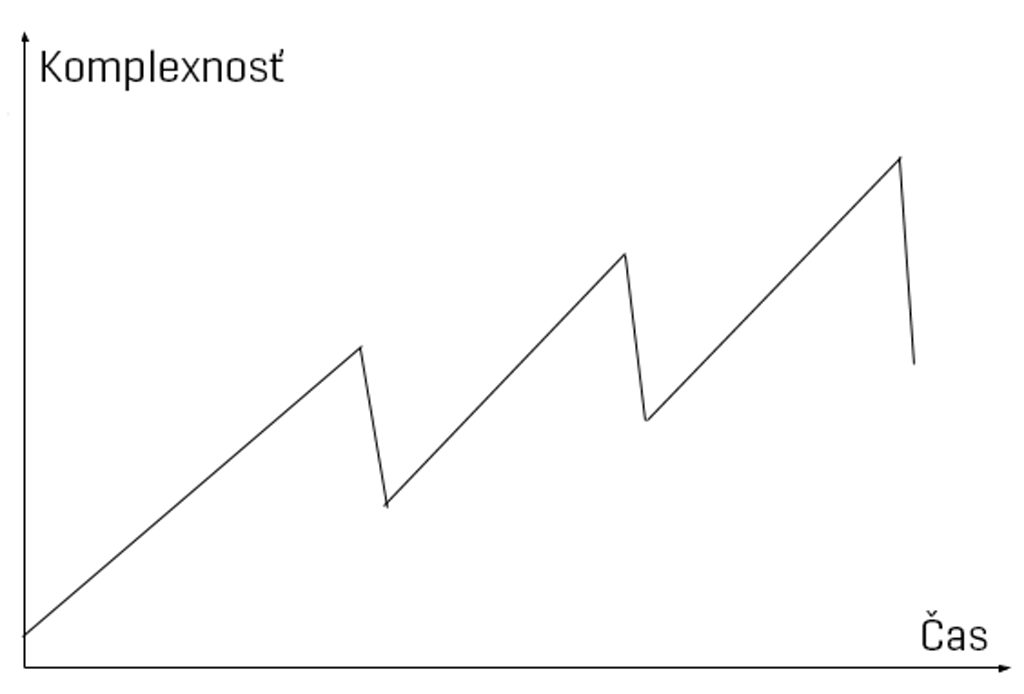
Cikcak krivka vývoja, ktorej beží na pomoc neurónová sieť
Jadrom každého vyhľadávača je zoraďovací mechanizmus, ktorý na základe odhadu relevantnosti dát určuje, aké poradia stránok a informácií je vhodné zvoliť.
Google sa za 20 rokov svojej existencie posunul od jednoduchého hľadania kľúčových slov a určovania významnosti webu pomocou tzv. PageRanku (založeného na tom, koľko iných stránok na daný web odkazuje), až k súčasným extrémne komplexným kusom kódu, zakladajúcich sa na tisíckach rozličných prvkov a nadväzností, ovplyvňujúcich poradie.
Niektoré prvky a kritériá sú pritom komplexné už natoľko, že je vhodné pre ich spracovanie použiť strojové učenie, respektíve moderné systémy hlbokého učenia, založené na konvolučných neurónových sieťach.
Je známe, že ešte v nedávnej minulosti sa Google nástupu umelej inteligencie vo svojich vyhľadávacích mechanizmoch bránil. A to aj napriek tomu, že v tomto odbore patrí k popredným svetovým vývojárom a neurónové siete používa v mnohých svojich produktoch (napríklad v prekladači, rozpoznávaní hovorenej reči v rámci Androidu, pri vyhľadávaní fotiek v rámci Google+, či dokonca aj v rámci systému odporúčaných videí na YouTube).
Situácia sa však zmenila začiatkom roku 2015, keď do svojho vlajkového produktu začal vkladať systémy vytvorené v rámci divízie Google Brain. Podľa toho sú aj tieto vyhľadávacie systémy pomenované ako RankBrain, čo je pomerne jasný odkaz na klasický PageRank.
Google začal s integráciou zľahka, ale už na konci prvého roku sa objavili prvé vágne vyjadrenia vyšších predstaviteľov spoločnosti, že RankBrain mechanizmy sa podieľajú „na značne veľkej časti“ spracovávania vyhľadávacích fráz.
Jeff Dean, hlava vývojového tímu Google Brain
To, v akom pomere dnes používa Google klasickú heuristiku a mechanizmy založené na neurónových sieťach, vedia len relevantné osoby vo vnútri firmy, ktoré obvykle verejne o daných veciach nehovoria. Koniec koncov, ide o jedno z najväčších know-how spoločnosti, s obrovskou hodnotou.
V tomto ohľade sú preto pre verejnosť veľmi cenné odhady Nikhila Dandekara, bývalého dlhoročného inžiniera vyhľadávača Bing, ktorý sa k problematike v jednom zo svojich zápiskov vyjadril. Podľa Dandekara je pravdepodobné, že aj keď Google v súčasnosti už používa zoraďovacie mechanizmy založené na hlbokom učení na mnohých miestach, najvrcholovejší zoraďovací mechanizmus bude pravdepodobne stále ešte heuristický, teda založený na klasických algoritmoch, vytvorených programátormi na základe skúseností, odhadov a intuícii správneho a dostatočného presného riešenia.
Všetko sa totiž odvíja od toho, že heuristické systémy sú v základe jednoduchšie pochopiteľné a manažovateľné, než systémy umelej inteligencie. Ak niečo nefunguje dobre, alebo si zmena situácie vyžaduje dodatočnú úpravu, u heruistického systému je možné ju ľahko vykonať zmenou aktuálnych parametrov, či pridaním nových.
Problémom klasických systémov je, že sa neučia a sú v základe statické. Ako postupne vývojári vylepšujú ich vlastnosti pridávaním výnimiek, nových parametrov a kalibrácií, zo zoraďovacieho mechanizmu sa stáva komplexná príšera, čoraz náročnejšia na prevádzku. Systémy založené na umelej inteligencii, ktorú v súčasnosti reprezentujú neurónové siete, stoja na opačnej strane spektra. V základe sú omnoho zložitejšou vecou na konfiguráciu, pričom v mnohých ohľadoch ide o nedostupnú čiernu skrinku, ktorú je v prípade problémov neraz nutné trénovať nanovo, alebo celkom prerobiť. Akonáhle je však systém hotový a plne funkčný, je omnoho menej komplexný, ako pokročilá heuristika a menej náročný na integráciu.
Jednoduché znázornenie vývoja vyhľadávačov, pri ktorom sa pravidelne znižuje komplexnosť nahradením stále zložitejších heuristických systémov prvkami umelej inteligencie, ktoré komplexnosť znížia
Výsledkom integrácie oboch prístupov je cikcaková krivka vývoja vyhľadávača, ktorú môžete vidieť na grafe. Vyhľadávač pri vývoji začína s heuristikou, pomocou ktorej výsledky zoraďuje, pričom vývojári postupne pridávajú čoraz viac parametrov, v snahe urobiť ho lepším.
Systém sa tak postupne stáva veľmi komplexným a náročným na údržbu a dáva tak zmysel znížiť jeho komplexnosť náhradou niekoľkých heuristických parametrov za účinné mechanizmy založené na hlbokom učení. Pomocou nich sa vývojovému tímu často podarí znížiť komplexnosť zoraďovacieho systému ako celku, bez toho aby to malo vplyv na jeho výkon.
Nasleduje ale ďalší cyklus pridávania funkcií a heuristických mechanizmov, až napokon opäť začne dávať zmysel aspoň časť z nich odovzdať do rúk umelej inteligencie. Vzhľadom na to, že na vyhľadávač sú kladené čoraz zložitejšie požiadavky, je nutné integrovať čoraz pokročilejšie mechanizmy.
Aj napriek schodom k nižšej komplexnosti sa teda v konečnom dôsledku krivka posúva smerom hore k vyššej komplexnosti. Vývojový tím vyhľadávača sa však nepochybne tento vzostup snaží udržať na minime.
Identifikácia obsahu obrázka konvolučnou neurónovou sieťou
Pri tvorbe vyhľadávačov budúcnosti, ktoré budú dominovať hľadaniu v budúcej dekáde, je posun k čoraz väčšej integrácii neurónových sietí celkom jasným cieľom. Nejde však o ľahkú úlohu a Google, Microsoft či Baidu majú pred sebou značnú výzvu. Súčasné vyhľadávacie systémy sú stále z väčšej časti založené na algoritmoch, ktoré sa riadia podľa pravidiel, stanovených ľuďmi.
Ak by vývojári len bezhlavo integrovali neurónové siete čoraz viac a prenechávali im opraty nad rozhodovaním, tak v prípade problémov a anomálií budú značne bezradní.
Situácia sa dá pomerne dobre prirovnať k psovi. Predstavte si, že postavíte mechanický stroj, ktorý dokáže nejako rozpoznávať pachy. Funguje pomerne dobre, ale v nejakých 15 % prípadov sa zmýli. Keďže viete presne, ako je postavený, môžete obrazne povedané „potočiť nejakými skrutkami“ a upraviť jeho konfiguráciu, v snahe chybovosť zmenšiť.
Dostanete sa na 10 % chybovosť, kde narazíte na limit. Stroj sa už viac nedarí zlepšiť. Následne začnete používať na detekciu pachov vycvičeného psa, ktorý je omnoho lepší a dáva lepšie výsledky. Problémom ale je, že aj on sa napríklad v 2 % prípadov zmýli a vy netušíte prečo. Môžete síce upraviť jeho tréning a napomínať ho, ale problémom je, že do hlavy psa nevidíte a netušíte, prečo sa práve v daných momentoch mýli a neviete, na základe akých pravidiel on sám jednotlivé pachy posudzuje.
V prípade konvolučných a iných neurónových sietí takisto nikto presne nevie, na základe akých pravidiel sa siete sami naučia obsah rozpoznávať. Ak ukážeme neurónovej sieti stotisíc obrázkov psov, pričom ju inštruujeme, že na polovici z nich je kokeršpaniel a na druhej polovici nejaký iný pes, neurónová sieť sa podľa toho kokeršpaniela naučí rozpoznávať.
Ak jej následne ukážeme novú fotografiu tohto psa, ktorú ešte nikdy nevidela, rozpozná ho na nej. Takto môžeme do sietí pumpovať rôzne iné tréningové dáta a naučiť ich rozpoznávať napríklad jednotlivé druhy ovocia, ľudské emócie podľa výrazu v tvári, či práve dôležitosť dát v naviazanosti na vyhľadávanie podľa jednotlivých fráz.
V momente ako ale sieť v jednom prípade z tisíca urobí chybu a zmýli si napríklad banán so žltým školským autobusom, nikto netuší, „čo konkrétne potočiť“, aby sa to už neopakovalo. Nevieme totiž, aké pravidlá si interne neurónová sieť vytvorila na správne rozpoznávanie obsahu, pretože sa obvykle nepodobajú ničomu ľudskému. A to je dôvod, prečo sa Google integrácii umelej inteligencie do vyhľadávania pomerne dlho bránil.
Možno si poviete, že na drobných chybách až tak nezáleží, ak je systém v konečnom dôsledku omnoho lepší. Je pravda, že konvolučné neurónové siete v rámci vyhľadávacích mechanizmov fungujú a fungujú extrémne dobre. Google to vie vďaka tomu, že o používaní prehliadača zbiera obrovské množstvo dát. Ak zadáte do políčka nejakú vyhľadávaciu frázu a následne klikáte na jednotlivé výsledky stránok, či na konkrétne obrázky, Google si o každom kroku vedie podrobnú štatistiku. Ak kliknete na prvú stránku a následne sa už nevrátite, zrejme ste našli, čo potrebujete a vyhľadávač správne odhadol, aká bola odpoveď na váš výraz. Ak sa rýchlo vrátite a vyhľadávaciu frázu upravujete, až pokým nezaznamenáte úspech, ide o cenné informácie o tom, aká bola správna odpoveď na vašu pôvodnú otázku, respektíve vyhľadávaciu frázu.
Dáta jednotlivca sú pravdaže samy osebe bezcenné a nič sa podľa nich nikdy neupravuje. Pri miliónoch či napokon miliardách hľadaní rôznych ľudí sa však začnú v rámci Big Data vynárať súvislosti, na základe ktorých je možné algoritmus modifikovať a ladiť do lepšej podoby. Rovnako je na základe nich možné aj posudzovať to, či výsledky, v ktorých pomáhajú rôzne neurónové siete majú lepšiu účinnosť ako systémy bez nich.
Andrew Ng (s manželkou), ktorý vedie vývojový tím umelej inteligencie vyhľadávača Baidu
Tento neoddiskutovateľný fakt však nijak nepomôže v tom, ak sa výsledky stanú v nejakej situácii nevhodnými či dokonca diskriminačnými a je ich nutné nejako potlačiť. Rovnako je veľmi nepraktické, ak treba umelo zvýšiť význam nejakej frázy, respektíve špecifických signálov, o ktorých vieme, že sú veľmi dôležité a neurónová sieť ich ešte stále za dôležité nepovažuje.
Práve tieto udalosti bránia tomu, aby sa stále nevyspelé systémy tohto typu zavádzali hlava-nehlava a používali takmer výhradne. Trénovať sieť nanovo pri každej takejto chybe je často veľmi nepraktické. Môžeme však očakávať, že v nasledujúcich rokoch, respektíve dekáde budú tieto systémy čoraz úspešnejšie a bezchybnejšie a budú teda integrované v stále väčšej miere. Ide teda o dobre viditeľnú zmenu internetových vyhľadávačov, určených pre budúce dekády.
Metamorfóza vyhľadávača na odpovedací stroj
Ďalšia veľká zmena vyhľadávačov sa odohráva v rámci priamej používateľskej interakcie. Týka sa prerodu čistokrvných internetových vyhľadávačov na odpovedacie stroje, v rámci ktorých sa mení princíp mechanizmu z „nájdenia textu s odpoveďou“ na „poskytnutie odpovede“. Na prvý pohľad to môže pôsobiť podobne, ale v skutočnosti ide o technicky celkom odlišnú vec.
V dnešných vyhľadávačoch už napríklad neočakávate, že ak zadáte výraz „Bratislava teplota“, musíte klikať na prvý či druhý výsledok v zozname stránok, aby ste sa k požadovanej informácii dopátrali. Očakávate, že Google vám túto informáciu/odpoveď priamo zobrazí, čo sa už dlhšiu dobu deje. Podobne, ak zadáte výraz „54 míľ na km“ (54 miles to km), chcete od vyhľadávača odpoveď. Nechcete výsledok vyhľadávania a odkaz na stránku, kde sa táto odpoveď nachádza. Tento prerod je postupný, ale s pribúdajúcimi rokmi môžeme očakávať, že vyhľadávače budú poskytovať čoraz viac takýchto priamych odpovedí. Významne to totiž súvisí s hlasovými asistentmi.
V ére digitálnych asistentov je veľmi dôležité, aby správny bol hneď prvý výsledok vyhľadávania, pretože hlavne z neho bude systém informáciu extrahovať. Ak sa spýtate asistenta ako Amazon Echo, Google Home či Microsoft Cortana kedy sa narodila herečka Lucy Liu, asistent musí odpovedať so správnym dátumom, bez tolerancie chyby.
Vyhľadávače Google či Bing tieto informácie extrahujú a poskytujú hneď na úvodnej stránke výsledkov, spoločne s odkazmi, čo môžu asistenti okamžite použiť. To môže do budúceho súboja týchto zariadení vážne prehovoriť. Extrakcia dát priamo na strane pokročilého vyhľadávacieho mechanizmu totiž bude vždy na vyššej úrovni, než ako by to robil koncový systém sám v rámci zobrazenia bežných výsledkov.
Google Echo a Microsoft Cortana tak majú v tomto smere pochopiteľne výhodu, pretože obe firmy majú svoje vlastné vysoko pokročilé vyhľadávače, ku ktorým asistenti môžu získať nadštandardný prístup.
Výsledkom tohto prerodu je, že v najbližších rokoch a dekáde budú mať používatelia čoraz menší pocit, že sú to oni, kto informáciu vyhľadáva. Interakcia s vyhľadávačom sa bude dať charakterizovať ako „kladiem otázku/dostávam odpoveď“, namiesto dnes stále ešte obvyklého princípu „píšem vyhľadávaciu frázu a vo vyhľadaných odkazoch si ja sám nájdem odpoveď“.
Do všetkého pritom prehovorí aj čoraz častejšie zadávanie vyhľadávacích výrazov hlasom. Ide totiž o dôležitú zmenu v rámci používateľskej interakcie, pričom rýchlosť adopcie tohto typu rozhrania je už značná. Tomu, prečo je to tak sme sa venovali podrobne v článku: Ovládanie hlasom útočí a jeho najväčšou zbraňou sú neurónové siete.
V súvislosti s hlasovým zadávaním nevyhnutne narastá aj dôležitosť vyhľadávania formou dialógu, teda nadväzujúcich otázok a odpovedí, v rámci ktorých musí hlasový asistent a vyhľadávač meniť charakter svojich odpovedí. Navyše, keď používatelia vyhľadávajú hlasom, obvykle je to z dôvodu, že sa fyzicky venujú niečomu inému, napríklad riadeniu auta, opravovaniu, držaniu dieťaťa či vareniu, čo môže výrazne ovplyvniť to, aký druh odpovedí, respektíve vyhľadaného výsledku potrebujú. A to presne súvisí s extrémne dôležitou vlastnosťou vyhľadávača budúcnosti, ktorou je vedomie toho, kde a v akej situácii sa používateľ nachádza.
Vyhľadávač, ktorý má topánky
Nevyhnutným smerom, ktorým sa vyhľadávače už roky uberajú, je neprestajné narastanie pochopenia toho, čo používateľ pri zadávaní vyhľadávacej frázy zamýšľal. Totožné slovo v odlišnom kontexte znamená odlišnú vec a vyhľadávač to musí rozpoznať. Používatelia pritom čoraz viac očakávajú, že im vyhľadávač „číta myšlienky“, respektíve že vyvodí správne kontext, podobne ako iný človek.
Medzi veľmi dôležité oblasti v najbližšom desaťročí bude patriť efektívne rozpoznávanie akútnosti a momentálnej relevantnosti. Typickým príkladom je napríklad hlasové zadanie vyhľadávacieho dotazu „kde je parkovisko?“.
Táto otázka nemá v bežnej komunikácii žiadny všeobecný zmysel. Neobsahuje totiž žiadne spresnenie, (napríklad: Ktoré je najbližšie parkovisko k Zemplínskej šírave?), takže sa nevyhnutne vzťahuje buď k predchádzajúcej komunikácii, alebo v prípade, že žiadna predošlá nadväznosť neexistuje, tak k aktuálnej situácii (riadite auto a nejaké parkovisko práve hľadáte). Vyhľadávač teda musí automaticky zareagovať tým, že vám poskytne informáciu o tom, kde je najbližšie parkovisko k vašej aktuálnej polohe.
Na polohe silno závislé vyhľadávanie v rámci smartfónov za posledné tri roky výrazne silnie
Google viaže vyhľadávané dáta k vašej lokalite už veľmi dlhú dobu a ako Slovák máte výrazne upravené výsledky oproti Rakúšanovi či Britovi, pretože vás skrátka prednostne zaujímajú. Ak vyhľadáte meno amerického herca, očakávate, že medzi prvými výsledkami budú odkazy na československú filmovú databázu a iné stránky, písané v slovenčine a nie napríklad v japončine.
Nastavenie vyhľadávača je pravdaže možné používateľsky zmeniť a držať a aj preto môžete dostávať slovenské výsledky aj vtedy, keď cestujete so svojím notebookom a smartfónom na opačný koniec sveta. Takáto úprava výsledkov je pravdaže veľmi jednoduchá a rudimentárna, vyplývajúca z národných domén a použitého jazyka.
Poskytovanie výsledkov naviazaných nielen na štát a mesto, ale rovno polohu s presnosťou na niekoľko metrov, je nadväzným krokom. Dôvodom je, že najpoužívanejší druh počítača, na ktorom vyhľadávame, je smartfón. Google v minulosti pomerne rýchlo prišiel na to, že nadväznosť vyhľadávania je veľmi dôležitá, a že pre posudzovanie toho, čo používateľ hľadá, je esenciálne dávať aktuálnu frázu do súvislosti s jeho predchádzajúcimi hľadaniami spred pár sekúnd. Nemenej dôležitým sa pritom stáva aj čas a presná lokalita, kde sa nachádza.
Zrejme viete, že Google v rámci Androidu a svojich mapových podkladov v základe zbiera informácie o polohe používateľov na základe GPS. Históriu svojej polohy si môžete prezrieť na mape a v prípade záujmu ju môžete aj zmazať. Kolekcia dát tohto druhu sa prevteľuje do mnohých veľmi dobrých funkcií, pričom medzi tie najlepšie ukážky patrí aktuálny stav premávky, ktorý si môžete na mapách zobraziť. Google v priebehu dňa ukazuje, ktoré cesty trpia zápchami a kde sa zdržíte a ktorým cestám by ste sa mali naopak vyhnúť.
Zber polohy používateľov Androidu prevtelený do monitoringu dopravnej situácie
Tieto dáta sú založené na anonymnom zbere GPS dát používateľov so smartfónom, ktorí sa podľa rýchlosti očividne pohybujú v dopravnom prostriedku a náhle výrazne spomaľujú, spoločne s ostatnými účastníkmi premávky. V rámci dát pritom nie je zložité rozpoznať, že niektoré dáta sú len „anomáliou“, ktorá nemá nič spoločné s premávkou, pričom ide napríklad o časté zastavovanie autobusu, električky či vodiča v dodávke doručovateľskej služby. Od hromadných dát zostávajúcich účastníkov premávky sa totiž jasne líšia.
V blízkej budúcnosti bude pre vyhľadávač extrémne dôležité vyvodzovať, kde používateľ stojí a čo má presne v dohľade. Nejde len o to, aby na otázku „kde je KFC“ či len „KFC“ poskytol polohu najbližšej reštaurácie rýchleho občerstvenia tohto typu a ukázal adresu, smer, otváracie hodiny a hodnotenie používateľov. Takto sú výsledky vyhľadávania upravované už dnes, pričom Google relevanciu lokálneho vyhľadávania zvyšuje výraznejšie od roku 2014, keď do svojho mechanizmu zaviedol zmeny s kódovým označením Pigeon (holub).
Cieľom takýchto úprav je postavenie vyhľadávača, ktorý s vami kráča mestom. Na minuloročnej vývojárskej konferencii I/O celú problematiku dobre vystihol výkonný riaditeľ Googlu Sundar Pichai, ktorý pri predvádzaní inteligentného asistenta povedal „Chceme vám pomôcť vykonávať veci vo fyzickom svete. Chceme každému používateľovi dať do ruky jeho vlastný Google“. Použil pri tom výstižný príklad, pri ktorom používateľ stojí pred slávnou, fazuľu pripomínajúcou sochou v Chicagu (Cloud Gate) a položí asistentovi/vyhľadávaču otázku „Kto toto navrhol?“. Správna odpoveď je vyvodená skrátka z toho, kde sa nachádza a na čo sa pravdepodobne pozerá.
Z tohto dôvodu bude postupne narastať aj rozdiel v správaní vyhľadávača na rozličných zariadeniach. Ak hľadáte informáciu súvisiacu s vašou lokalitou na svojom notebooku a desktope, teda na nemobilných počítačoch používaných obvykle na stoloch, zvyčajne niečo plánujete. Ide napríklad o to, do akej reštaurácie pôjdete zajtra či za pár hodín, kde sa nachádza nejaký obchod kam sa chystáte, alebo kedy presne sa začína predstavenie filmu, na ktorý sa tešíte. Hľadania v rámci vášho blízkeho fyzického okruhu, ktoré vykonávate na smartfóne, sú však naproti tomu často celkom odlišné a ľahko sa môžu týkať vašej momentálnej akcie behom nasledujúcich minút či sekúnd. A vyhľadávače budúcnosti s tým budú musieť počítať.
Porozumenie časti obrázka a rozlúsknutie video výzvy
Vyhľadávanie multimédií je esenciálnou súčasťou internetových vyhľadávačov. Google vyhľadávanie obrázkov integroval do svojho vyhľadávača v roku 2001, pričom v tej dobe šlo výhradne o vyhľadávanie na základe toho, ako sa súbor obrázka volal, v akom textovom kontexte sa nachádzal a aký bol jeho popis na webe. Kým v roku 2001 Google indexoval 250 miliónov obrázkov, v roku 2005 už šlo o miliardu a v roku 2010 o desať miliárd. V tejto dobe pritom začal výraznejšie zavádzať pokročilejšie detekčné systémy, schopné triediť obrázky do kategórií podľa ich vizuálneho prejavu, ako je napríklad prevládajúca farba.
Od roku 2011 je dostupná funkcia pre reverzné vyhľadávanie, pri ktorej môžete hľadať obrázok pomocou obrázka samotného, bez potreby písania textu. Stačí ukázať jeho adresu alebo ho nahrať zo svojho počítača a vyhľadávač k nemu nájde kópie. V tomto procese dochádza k analýze obrázka, pri ktorom sa rozpoznávajú farby, textúry, body a jednotlivé línie tvarov, ktoré zobrazuje. Výsledkom je vygenerovaný dátový odtlačok, ktorý Google porovná s databázou generovaných odtlačkov miliárd iných obrázkov a rozpozná zhodu. Ide o výbornú funkciu, ktorá používateľom umožňuje hľadať vyššie rozlíšenia konkrétneho obrázka, alebo k nim vyvolávať asociácie typu kedy sa obrázok na internete po prvýkrát objavil a v akej súvislosti.
Ďalším krokom vpred v tomto smere je identifikácia reálneho obsahu, pomocou konvolučných neurónových sietí. Tá už dnes prebieha vo veľkej miere a mimoriadne úspešne, čomu sme sa aj podrobne venovali v článku Človek vs. konvolučné neurónové siete. Systémy tohto typu sú dnes zavádzané v rámci katalogizovania fotografií, čo dobre reprezentuje napríklad aplikácia Fotky Google.
V rámci nej cloudové systémy umelej inteligencie Googlu detegujú, na ktorej fotke ste vy, na ktorej vaša sestra, na ktorej váš pes a podobne (roztriedenie je pravdaže len na rozličné osoby bez mena, pomenovanie si vykonáte sami). Na podobnom základe sú založené aj mnohé aplikácie, ktoré dokážu identifikovať odfotený kvet, rasu psa a podobne. Je tak prakticky nevyhnutné, že aj tie najrôznejšie typy obrazového obsahu bude v blízkej budúcnosti možné identifikovať aj v rámci internetových vyhľadávačov.
Microsoft zaviedol detekciu tváre do vyhľadávania obrázkov vo vyhľadávači Bing
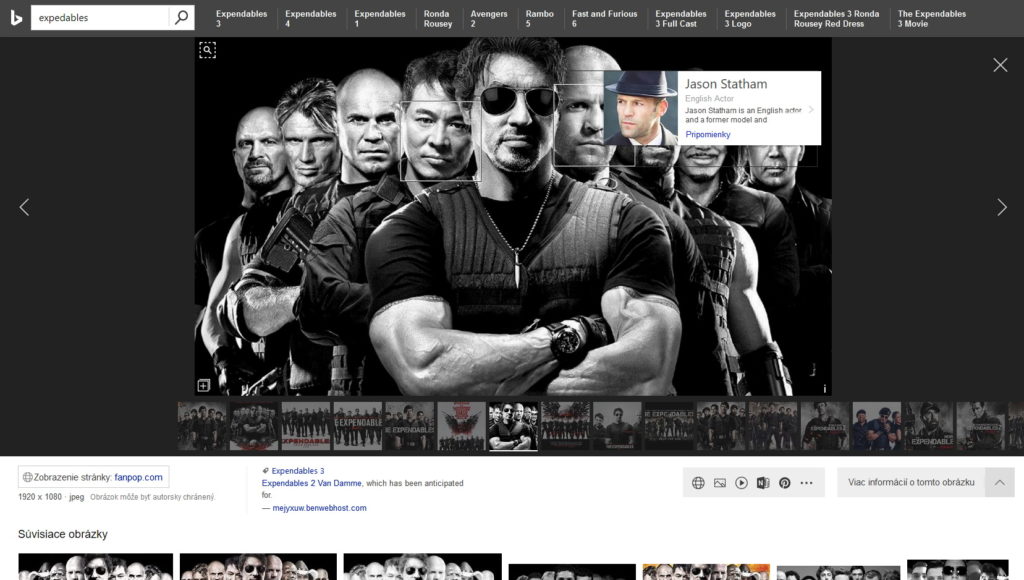
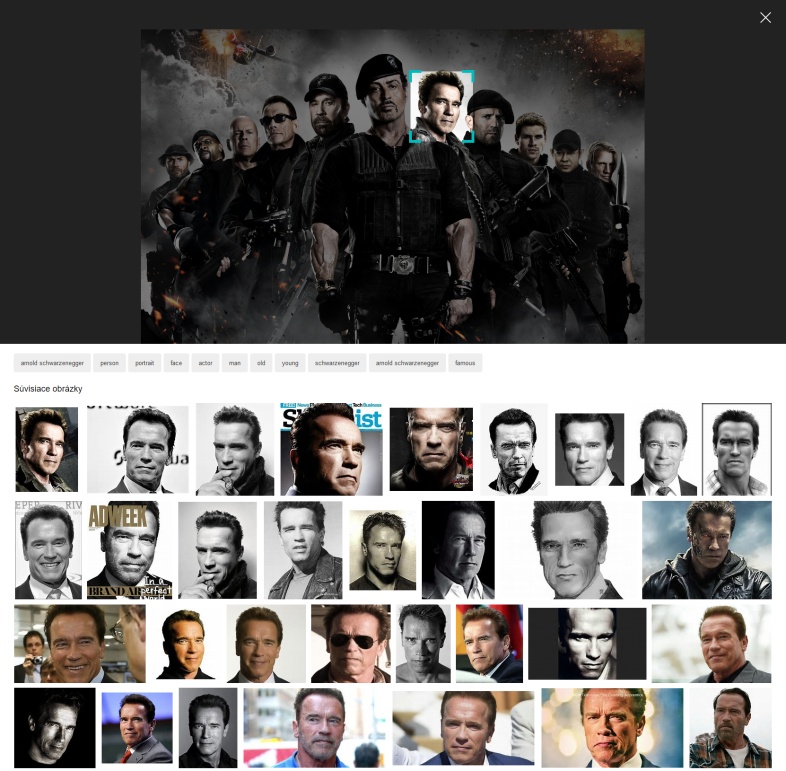
Dvere do tejto éry začal otvárať Bing od Microsoftu, ktorý umožňuje reverzné hľadanie obrázka podobne ako Google. Nedávno však svoje schopnosti v tomto smere značne rozšíril a pri otvorení obrázka v rámci vyhľadávača si môžete okrem klasických detailných informácií o veľkosti, či súvisiacich hľadaní všimnúť aj malú lupu v jeho ľavom hornom rohu (objaví sa v momente, ako nad obrázok posuniete kurzor myši). Ide o funkciu „hľadať v rámci tohto obrázka“, ktorá po kliknutí zobrazí označovací nástroj, určený na identifikáciu a reverzné vyhľadávanie časti obrázka.
Môžete tak označiť napríklad tvár osoby či objekt, ktorý posúdi neurónová sieť a podľa možností ho správne identifikuje a ponúkne výsledky. Na obrázku si môžete všimnúť plagát filmu Expendables, v rámci ktorého po označení tváre konkrétneho herca neurónová sieť Bingu tvár rozpozná a ponúkne vám jeho meno a súvisiace vyhľadávanie iných fotografií či relevantných informácií.
Nasledujúcou métou je video vyhľadávanie, čo je omnoho komplexnejší problém, pretože obsah je tvorený obrovskou sériou nadväzujúcich obrázkov. Súčasný video obsah sa vyhľadáva predovšetkým pomocou názvu, kľúčových slov a takisto nadväznosti vzhľadom na správanie používateľov a ich výber (napríklad v rámci YouTube).
Do hry čoraz viac vstupuje aj rozpoznávanie hovorenej reči pomocou rekurentných neurónových sietí, na základe čoho sú vytvorené titulky, ktorých obsah môže byť takisto použitý na identifikáciu obsahu. Automatické identifikovanie obsahu podľa obrazovej informácie je logickým krokom v poradí, s ktorým sa budeme v budúcej dekáde stretávať čoraz viac.
Vyhľadávanie podľa časti obrázka a identifikácia podobného obsahu spustená vo vyhľadávači Bing
Systém založený na konvolučných neurónových sieťach totiž môže obrazový obsah posudzovať a vytvoriť automaticky zoznam kľúčových slov, napríklad podľa hercov, ktorých rozpozná, druhov zvierat či prostredia. Pokročilejšia forma identifikácie môže rozpoznávať napríklad aj emócie osôb, činnosti, ktoré vykonávajú a podobne. Vo výsledku by teda mohla odpovedať na vyhľadávaciu frázu „Emma Stone ide v aute a plače“ a ponúknuť správny video obsah.
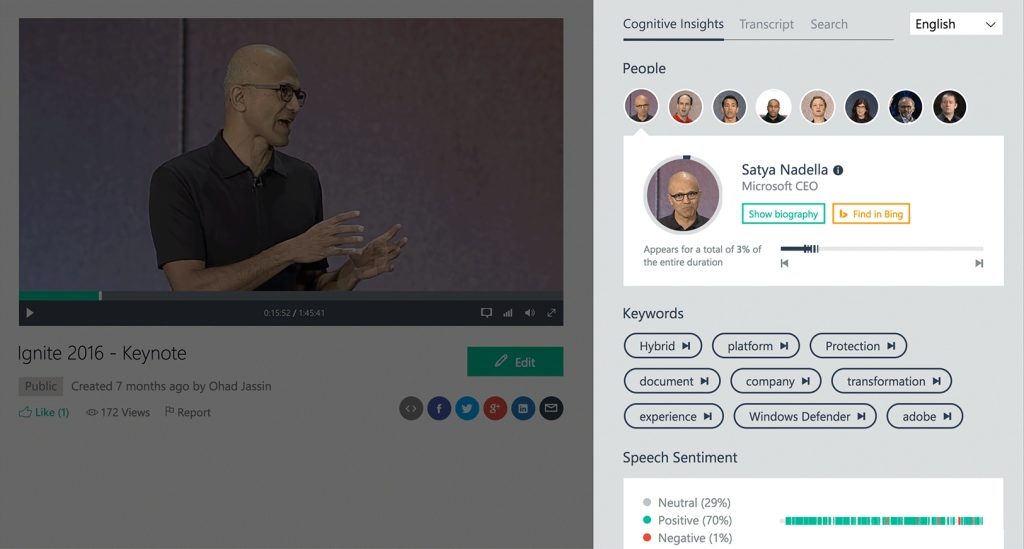
Funkcie na identifikáciu obrazových prvkov videa sú v súčasnosti čiastočne dostupné v rámci samostatných služieb. Medzi dobrú ukážku patrí Video Indexer od Microsoftu (v minulom roku, keď začal byť dostupný, vystupoval ešte pod názvom Video Breakdown), ktorý ťaží z toho, že Microsoft patrí k svetovej špičke vývojárov konvolučných neurónových sietí.
Platforma Video Indexeru obsahuje niekoľko služieb Azure a zároveň aplikačné rozhranie (API), určené na extrahovanie kognitívnej informácie z obsahu videa. Používatelia a zákazníci služby môžu na platformu nahrať svoje videá a nechať ich systémom neurónových sietí analyzovať. Pri procese dochádza k vytvoreniu textového prepisu, v rámci ktorého dôjde k záznamu nielen zvukovej informácie, ale aj vizuálnej (napríklad pomocou popisu: v tejto scéne chlapec vo veku 10 až 15 rokov skáče na skateboarde cez prekážku).
Systém umožňuje rozpoznávať rôzne osoby podľa tváre i hlasu a dokáže extrahovať takisto základnú povahu pozitívneho alebo negatívneho kontextu reči. Prítomné je takisto optické rozpoznávanie znakov, umožňujúce extrahovať text napríklad zo záberu na popisnú tabuľu či zo záverečných titulkov.
Identifikácia obsahu videa v rámci platformy Video Indexer od Microsoftu
Výsledným produktom je prepis a zoznam kľúčových slov naviazaných na jednotlivé časové známky, čo umožňuje vo videu vyhľadávať napríklad podľa toho, kedy bolo po prvýkrát použité nejaké slovo (podľa prepisu hovoru) alebo skočiť do momentu, keď sa po prvýkrát objavil v zábere nejaký konkrétny herec (podľa rozpoznania tváre). To zároveň umožňuje aj účinné kategorizovanie obsahu, čo je veľmi dôležité napríklad pre strihačov, ktorí potrebujú rýchlo získať konkrétne zábery z obrovského objemu rôzneho videa, z ktorého tvoria napríklad kompiláciu.
Pre mnohé firmy je dobrá katalogizácia obsahu súčasťou biznisu, pričom ide napríklad o Pond5, čo je jedna z najväčších videobánk na svete. Na rozdiel od klasických fotobánk ako Shutterstock či Getty Images sa Pond5 zameriava na video obsah, určený pre použitie na webe a takisto napríklad v ilustračných videách v rámci TV a iných spravodajských organizácií.
Firma v minulom roku zaviedla systém umelej inteligencie NextSense, pomocou ktorého rozpoznáva kľúčové slová pre popis videa, ako je napríklad konkrétna rasa zvierat a podobne, čo zlepšuje vyhľadávanie. V základe ide o konvolučné neurónové siete, ktoré identifikovali niekoľko miliónov klipov a pokračujú v tom aj pri pridávaní tých nových. Používatelia tak majú možnosť obsah hľadať detailnejšie. Ak napríklad niekto hľadá video tigra, bežný systém mu poskytne stovky či dokonca tisíce rôznych videí, ktoré následne musí používateľ prezerať a hľadať to vhodné.
Vďaka lepšiemu katalogizovaniu neurónovou sieťou ale môže vybrať rýchlo to, ktoré sa najviac blíži k tomu, čo hľadá a následne si nechať zobrazovať iba tie videá, ktoré napríklad majú záber na tigra z podobného uhla, majú rovnaké nasvietenie či podobné pozadie. Výrazne sa tým hľadanie žiadanej scény urýchli.
Videobanka Pond5 spustila automatickú identifikáciu obsahu svojich videí pomocou konvolučných neurónových sietí
Je nepochybné, že systémy podobného typu si budú v najbližšej dekáde hľadať cesty do internetových vyhľadávačov. Ak si dnes napríklad spomeniete na nejakú scénu z TV seriálu a neviete v ktorom diele bola, môžete Google použiť. Vaše vyhľadávanie je často úspešné vďaka tomu, že seriál sledovalo obrovské množstvo ľudí, niekto sa už napríklad na nejakom diskusnom fóre podobnú otázku spýtal a nejaký iný používateľ si spomenul a odpovedal mu.
Alternatívne niekto mohol danú scénu uploadovať na YouTube s názvom, ktorý ju dobre ilustruje a podľa ktorého ju hľadáte. Ak ale nemáte šťastie, zostanete bez výsledku. Automatická identifikácia obsahu videa má potenciál všetko zmeniť a výrazne vyhľadávače zlepšiť. Je dosť dobre možné, že pokročilé vyhľadávače budúcnosti už dokážu odpovedať aj na extrémne a veľmi podrobné štatistické otázky typu – koľko minút bol v obraze herec Tom Hanks vo filme Zelená míľa, ako často sú Rachel a Ross v jednom zábere v seriáli Priatelia a podobne.
Ak sa pozrieme na vývoj vyhľadávačov z väčšej perspektívy, cieľ sa zdá jasný. Budúcnosť je skutočná vyhľadávacia syntéza, pri ktorej používateľ nerieši, kde sa hľadá. Vyhľadávače budú úspešne vyhľadávať v texte, obrázkovom obsahu, video obsahu, a to nielen podľa základných popisov, ale aj podľa vlastnej analýzy toho, čo sa v danom obsahu deje. Systémy budú čoraz viac reagovať na vašu polohu a posledné činnosti a budú prinášať vhodnejšie a presnejšie výsledky, ako kedykoľvek predtým. A používatelia, ako to už pri technológiách bežne býva, to všetko budú považovať za úplnú samozrejmosť, ktorá akoby tu bola odjakživa.