Ako bude vyzerať svet, v ktorom ktokoľvek bude môcť veľmi jednoducho vygenerovať napríklad videozáznam politika, hovoriaceho a robiaceho veci podľa jeho želania? Ako budeme všetci pristupovať k tomu, čo vidíme na obrazovke, ak generovaný hlas a obraz ľudí bude na nerozpoznanie od reálneho záznamu? Táto doba už je totiž veľmi blízko.
Len si to predstavte. Jedného dňa vám na sociálnej siete, v komunikátore či v e-mailovom schránke pristane správa, v ktorej sa bude nachádzať odkaz na nové YouTube video. To je BOMBA! Hlásia vám kolegovia a známy vopred. Video si pustíte a vidíte v ňom prezidenta, ako stojí na pódiu a úprimne sa pre davom ľudí priznáva k nevere, krádeži či k vražde. Vyzerá ako on, hýbe sa ako on, hovorí ako on. Je to skrátka on. Až na to, že to nie je on. Ide o video generované pokročilým mechanizmom umelej inteligencie, ktoré je absolútne na nerozoznanie od reality.
To, že obrazovú informáciu je možné podvrhnúť je koncept, s ktorým sme všetci dlhodobo oboznámení. Dlhé roky ho poznáme hlavne v súvislosti s fotografiami. Ak dnes vidíme nejakú podozrivú fotografiu, ktorá by mohla byť fotomontáž, tak aj v prípade, že jej podvrh takmer dokonalý, mnoho ľudí zapochybuje a povie „to je sfotošopované“. Naznačujú tým, že ide o vizuálny podvrh, ku ktorému je vo veľkom množstve prípadov použitý najpopulárnejší rastrový editor obrázkov na svete, Adobe Photoshop. Do všetkého prehovárajú takisto rôzne kamerové triky a vizuálne efekty, ktoré sa nás pokúšajú vo videách presvedčiť napríklad o zázračných únikoch pred istou smrťou, kúzlach či nadprirodzených javoch. Aj v ich prípade mnoho laikov často zakričí vetu o Photoshope, i keď tu už sa pravdaže používajú programy iného typu (napríklad Adobe After Effect).
Bežný človek sa pri hodnotení pravosti či nepravosti videa riadi obvykle len zdravým rozumom. To obvykle stačí, ale skúsenejšie technické oko, ktoré slabiny súčasných technológií pozná, je dnes ešte vždy schopné odhaliť slabé miesta vo vizuálnom efekte a poukáže na ne. Dvere k tomuto faktu sa však pomerne razantne začínajú zatvárať, k čomu prispieva akcelerovaný vývoj v systémoch umelej inteligencie, konkrétne v neurónových sieťach.
Výsledkom týchto riešení je nová možnosť generovať vierohodné videozáznamy osôb, ktoré sa nikdy nestali. Nejde pri tom len o videozáznamy podvrhnutých rozhovorov, doznaní či video dôkazov o trestných činoch politikov, celebrít, či bežných ľudí. Ide aj o možnosť tvorby pornografie, s populárnymi osobami, ktoré s ňou v skutočnosti nemajú nič spoločné.
Toto všetko bude znamenať prechod do celkom novej éry. Éry bez video a audio dôkazu. Nielenže nebude možné veriť tomu, že konkrétne usvedčujúce video je naozaj realita, ktorá sa udiala. Pôjde takisto aj opačný efekt, kedy sa reálne video označí v rámci obrany za podvrh, pretože nebude možné vylúčiť to, že ním naozaj je. Výsledkom bude, že mnoho ľudí bude presvedčených o falošnej realite, ktorá sa nikdy nestala, zatiaľ čo podobné množstvo ľudí bude skalopevne presvedčených o neplatnosti reality, ktorá sa naozaj stala, pretože jej z dôvodu možného podvrhu neuveria.
Úprimný prejav či priznanie na kameru, ktoré sa nikdy nestalo
V rámci celej problematiky si je vhodné uvedomiť, že sa netýka len politikov, celebrít či skrátka významných osôb, ktoré sú dostupné na takmer nekonečnom zástupe profesionálnych videí. Človek nemusí byť celebrita, aby „tona“ videozáznamu bola pre neho dostupná.
V súčasnosti sa nachádzame vo svete, kde je možné triviálne fotografovať a natáčať videozáznam, pretože väčšina ľudí nosí zariadenie s touto schopnosťou neustále pri sebe. Okrem toho, populárne aplikácie ako Skype či FaceTime, ktoré sú používané na video hovory nielen v súkromnom, ale aj pracovnom prostredí, je možné pri hovore bez akýchkoľvek problémov nahrávať bez vedomia osoby na druhej strane.
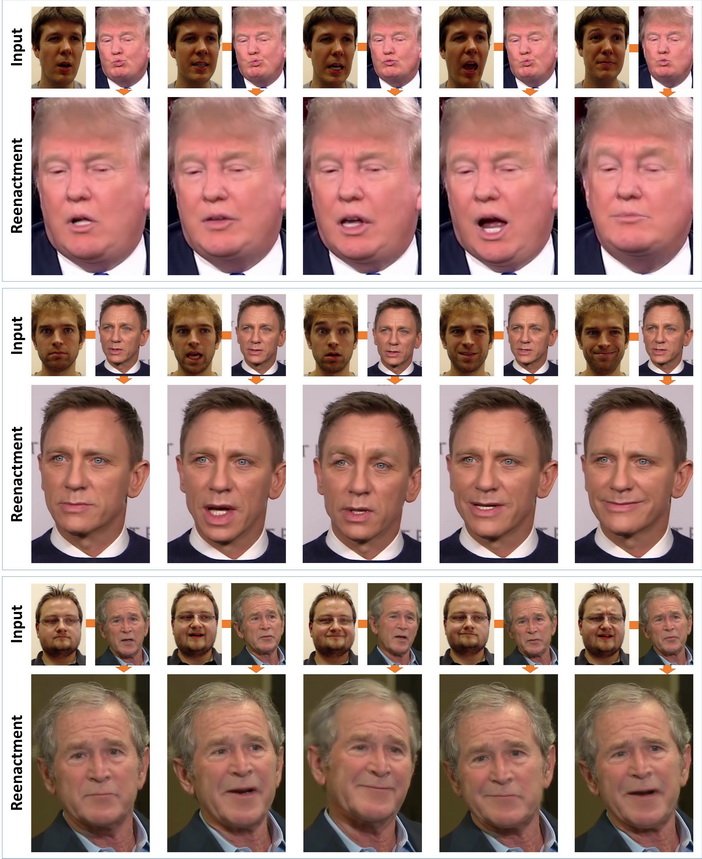
Presun mimiky inej osoby do videa v rámci technológie Face2Face
S vytváraním falošných videozáznamov, pri ktorých sa dodatočne vložili do obrazu tváre napríklad ústa inej hovoriacej osoby, sa stretávame už desiatky rokov. Ešte donedávna boli produkované snímky tohto typu mimoriadne nevierohodné a neoklamali by prakticky nikoho. S pokrokom vo filmovom priemysle a vizuálnych efektoch sa však situácia neprestajne lepšila. Aby dnes mimika v rámci animovanej postavy alebo pokročilého vizuálneho efektu vo filme vyzerala vierohodne, používa sa obvykle jej priamy digitálny transfer.
Na tvári herca sa vytvoria záchytné digitálne body, ktoré následne slúžia ako podklad na vytvorenie 3D modelu generovanej postavy, ako napríklad Hulka v moderných filmoch zo série Avengers, alebo napríklad aj Glooma z trilógie Pánovi prsteňov. Pohyb tváre tak nevyzerá umelo, ale veľmi prirodzene, pretože de facto prirodzený naozaj je. Tieto pokročilé mechanizmy však nemusíme aplikovať len na 3D model, ale aj na videozáznam reálnej osoby.
V roku 2016 vzbudila mediálnu pozornosť technológia Face2Face, ktorá bola výsledkom vedeckej práce nemeckých výskumníkov z Technickej univerzity v Mníchove, Výskumného inštitútu Maxa Plancka pre Informatiku a Erlangensko-norimberskej univerzity.
V rámci nej boli použité YouTube videozáznamy rôznych známych osôb, ako napríklad politikov a hercov, ktorých mimika bola alterovaná v reálnom čase na základe pohybov osoby, sediacou pred štandardnou webkamerou. V demonštračnom videu môžeme vidieť napríklad Georga Busha, Baracka Obamu, Donalda Trumpa či Vladimíra Putina, pričom ich mimika a pohyb úst sa zrkadlí podľa mimiky vzorovej osoby, akoby šlo o šikovného bábkara, ťahajúceho za nitky.
Pre osobu na videu a takisto osobu pred kamerou sa vytvoril 3D model tváre, ktorý následne slúžil na transfer. Ako náhle bol tento proces hotový, samotný transfer mimiky už mohol prebiehať v reálnom čase a bez potreby nejakého špeciálneho výpočtového výkonu.
Zvládol ju aj celkom obyčajný počítač. Pri predvádzaní vývojový tím skrátka len zaznamenával rozprávanie a výrazy tváre hovoriacej osoby obyčajnou webkamerou a jeho mimika sa v reálnom čase aplikovala na tvár cieľovej osoby vo videu, takmer bez akejkoľvek očividnej bariéry a meškania. Pohyb úst bol natoľko dokonalý, že by bez problémov umožňoval aj čítanie z pier. Prekonával aj očividné slabiny, ako napríklad renderovanie vnútra úst.
Aj keď šlo v tomto prípade len o presun mimiky a nie hlasu (videá boli nemé), tak aplikovanie takýchto zmien v reálnom čase predviedlo verejnosti veľmi zaujímavý dôsledok vývoja softvérových technológií. Mechanizmus tohto typu totiž z princípu umožňuje, aby bol videozáznam jedného rozhovoru takmer neznateľne použitý na vytvorenie iného rozhovoru či prejavu, s falošným obsahom, pričom tým hlavným zlomovým faktom je, že môže byť vykonaný aj v živom prenose.
Aj keď technológia nebola dokonalá a mierna čudesnosť niektorých pohybov nakoniec vždy prezradila, že ide o podvrh, pre posúdenie je treba uvažovať v horizonte 5, 10 či 15 rokov. Malé zlepšenie totiž môže pokoriť hranicu chýb, ktoré sme schopní postrehnúť a videozáznam bude pôsobiť plne realisticky.
To by znamenalo, že by bolo technicky možné, aby sa reálna osoba (prezident či iný politik, alebo ktokoľvek iný) verejne podvrhnuto priznala napríklad k nejakým nekalým činom, alebo sa zdiskreditovala pri vysielaní (falošnej) živej debaty. Bolo by totiž možné vysielať video prenos, v ktorom by videozáznam danej osoby vďaka „bábkarovi“ mimo záberu odpovedal a reagoval aj na priame otázky telefonických divákov, či reportérov. V skutočnosti by pravdaže odpovedal podvodník a jeho slová by sa prevteľovali do videa obete.
Technológia z projektu Face2Face mala však jednu očividnú nevýhodu. Ak odhliadneme od očividného faktu, že bola nemá, dôležitou slabinou bolo, že mimika nepatrila obeti, ale „bábkarovi“. To je významný rozdiel, pretože podobne ako farba hlasu, aj mimika tváre je veľmi špecifická pre každú osobu zvlášť a dá sa rozpoznávať.
Každý človek má nejaký základný spôsob mimického a celotelného prejavu, sprevádzajúceho jeho vyjadrovanie. Či už ide o pohyby rúk, nakláňanie hlavy, grimasy či iné pohyby, akýkoľvek pozorovateľ si ich pomerne rýchlo začne všímať tak, ako samotné metódy vyjadrovania v podobe intonácie, prestávok či špecifických „premosťovacích“ zvukov, ako „ehm“ a podobne. O spadnutie tejto prekážky sa však postarali v posledných mesiacoch nový pomocníci – neurónové siete.
Generovanie videa neurónovými sieťami v akcii
Za posledných dvanásť mesiacov sa alternácia videozáznamu posunula o masívny kus vpred. Demonštráciu tohto faktu sme mohli vidieť minulý rok na výbornej ukážke, ktorá je súčasťou akademickej vedeckej práce nazvanej Syntetizovanie Obamu: učenie synchronizácie pier na základe audio zdroja (Synthesizing Obama: Learning Lip Sync from Audio), ktorú publikovali Supasorn Suwajanakorn, Steven Seitz a Ira Kemelmacher z Washingtonskej univerzity.
Baracka Obamu si výskumníci vybrali za svoj cieľ z jednoduchého dôvodu. Na YouTube sa nachádza viac ako 17 hodín kvalitného video záznamu jeho rozličných prejavov, v rozpätí ôsmich rokov jeho prezidentskej činnosti, čo je zhruba dva milióny jednotlivých snímok. Ide o zväčša profesionálne videá v HD kvalite, s veľkým detailom tváre, pričom sa na ne nevzťahuje autorské právo (tzv. public domain, teda verené vlastníctvo), čo umožňuje ich prakticky neobmedzené použitie v rámci vedeckého výskumu.
Generovanie pohybu pier Baracka Obamu neurónovou sieťou
V tejto výskumnej práci vidíme badateľný prielom v oblasti generovania mimického pohybu na základe zvukového prejavu, pričom samotná mimika nepatrí cudzej osobe, ale ozajstnému vlastníkovi. Inak povedané, nielenže videozáznam danej osoby hovorí čo chceme, ale daná osoba pri vyslovení jednotlivých slov vyzerá presne tak, ako by vyzerala, keby dané vety hovorila naozaj. Namiesto výmeny, respektíve aplikovania mimiky od iného človeka (Face2Face), tak mimiku v tomto prípade tvorí plne automatický systém.
Generovanie umelého pohybu úst na základe audia je extrémne ťažká úloha. Nejde pri tom len o to, že jednorozmerný signál potrebujeme namapovať a aplikovať na pohybujúci sa obrázok. Ide hlavne o to, že ľudia sú nemierne citliví na aj tie najmenšie zmeny mimiky, čo je dôležitá a evolučne extrémne vycibrená vlastnosť pre sociálnu interakciu. Z miniatúrnych pohybov tváre totiž extrahujeme veľmi podrobne pocity osoby, na ktorú sa pozeráme.
Obvykle ich veľmi úspešne vieme vycítiť (v realite odpozorovať), bez toho, aby sme si to priamo uvedomovali, pričom sa riadime aj tými najdrobnejšími záchvevmi konkrétnych častí tváre (predovšetkým úst a okolie očí). V súvislosti s vytváraním imitácie to ale znamená, že aj drobná nezrovnalosť pri generovaní falošného snímku nám okamžite udrie do očí a pôsobí na nás synteticky, roboticky a skrátka veľmi neprirodzene. Často je to pri tom až strašidelné, čo je dobre známe napríklad z rozprávajúcich herných postáv, súčasných „sekajúcich sa“ humanoidných androidov a podobne.
Na demonštračnom videu z Washingtonskej univerzity môžeme vedľa seba vidieť štvoricu videí Baracka Obamu, ktorý hovorí ten istý text. Na každom videu vidíme iný detail jeho tváre, iné prostredie a iné pohyby aj osvetlenie scény. Každý zo štyroch príhovorov pôsobí veľmi prirodzene a vyzerá to, akoby Obama vskutku nahral štyri rôzne videá, v ktorých hovorí tie isté vety. V skutočnosti sú však všetky umelé, i keď na pohľad vyzerajú prakticky dokonalo.
Občas je na niektorom vidieť slabé miesto, avšak ide vskutku len o drobnosti, ktoré sa dajú ľahko zameniť za seknutie v internetovom prenose a podobne. Ak by ste ktorékoľvek video videli bez predchádzajúceho upozornenia na to, že je falošné, pravdepodobne by ste si toho nikdy nevšimli
Produkciu videa v takejto kvalite, takmer na nerozpoznanie od originálu, by nezvládol žiadny ľudský animátor, ani imitátor, ktorého tvár by sme mapovali. Výsledok práce výskumného tímu generoval systém umelej inteligencie, založený na metódach tzv. hlbokého učenia. V jadre technológie sa nachádza rekuretná (zvratná) neurónová sieť, ktorá bola na niekoľkých hodinách videozáznamu Baracka Obamu dlhodobo trénovaná k tomu, aby si všímala špecifickú mimiku a pohyby hlavy a celého tela pri vyslovení jednotlivých slov a slabík a takisto jeho vetnú skladbu.
V základe si všímala toho, akú variabilitu dosahoval obraz v jednotlivých zvukových prejavoch a učila sa predpovedať jeho podobu na základe zvukovej krivky. Je treba si uvedomiť, že v zdrojových videách bola tvár Baracka Obamu vždy inak natočená či inak nasvietená a medzi jeho pohybmi sa vyskytuje variabilita. Tak ako sa neurónová sieť učí rozpoznávať napríklad auto na konkrétnych fotografiách áut, pričom po naučení je už táto sieť schopná auto rozpoznať na fotografiách, ktoré nikdy nevidela.
V tomto prípade teda používala svoje naučené schopnosti k tomu, aby alterovala videozáznam tak, aby obrazový výstup odpovedal kritériám „esencie“ prejavu. Nešlo teda o kopírovanie záznamu úst z nejakej existujúcej časti videa. Neurónová sieť skrátka vstupné audio transformovala do podoby tvaru 3D textúry úst, čeľuste a líc, aké považovala na základe svojich „vedomostí“ za správne. Následne bol tento obraz vylepšený o detaily, ako zuby a povrch kože a spodná časť tváre bola následne integrovaná do regulárneho video záznamu.
Výsledok bol vskutku dych berúci. Vo videu je pekne vidieť, ako sa výsledok výrazne zlepšuje s dostupným tréningom. Kým pri pár minútach či desiatkach minút videozáznamu je generovaná podoba značne trhaná a realite neodpovedá takmer vôbec, s pribúdajúcimi hodinami sa rýchlo zlepšuje a pri 14 hodinách, ktoré boli použité pri demonštrácii, už je výsledok takmer dokonalý.
Syntetická hlasová kópia na dosah
To, ako tento mechanizmus môže byť použitý na zavádzajúce účely, môžeme vidieť v závere videa Baracka Obamu, kedy sa na vytváranie plne generovanej mimiky jeho hovoru nepoužije už jeho originálny záznam hlasu, ale prejav jeho hlasového imitátora (i keď nie veľmi dobrého). Neurónová sieť generuje mimiku aj pri ňom stále rovnako dobre a presne tak ako očakávame. Ak by sme chceli vytvoriť ozaj vierohodné falošného video tohto typu, jednou z možností je použiť šikovného ľudského hlasového imitátora, ktorých sa pohybuje po svete veľa. Žiadny imitátor však nie je dokonalý. Čo teda ak by sme neurónovú sieť netrénovali len na obraz, ale rovno aj na zvuk?
Súčasný stav kvality syntézy hlasu si väčšina ľudí oprávnene spája s aktuálnou podobou hlasových asistentov, integrovaných v smartfónoch či inteligentných reproduktoroch. To je momentálny komerčný stav tejto technológie, pričom aktuálny stav je oproti situácii z pred pár rokov masívne vzdialený. V minulosti bol syntetizovaný hlas enormne robotický a sekaný, pričom na ňom bolo veľmi počuť to, že je vlastne zloženinou nahratých zvukov.
Projekt VoCo je budúci editačný program hovorenej reči od Adobe
Dominantným riešením softvérového čítania textu bola dlhodobo tzv. konkatenačná syntéza, ktorej starú podobu celkom určite poznáte napríklad zo syntetizátora reči nedávno zosnulého fyzika Stephena Hawkinga, na ktorej bol počuteľný silný robotický prejav. Pri tejto metóde sa používa obrovská databáza nahratých krátkych úsekov reči v podobe slabík, písmen a iných krátkych štruktúr, ktoré sú následne softvérom kombinované do slov a viet.
Výsledkom je, že je prakticky nemožné zmeniť výrazne hlas na inú osobu bez toho, aby ste nenahrali novú databázu zvukov a rovnako nie je možné ani operovať s dôrazom či emóciami v reči. Zlepšením v tomto smere bola tzv. parametrická syntéza, pri ktorej sú zvukové dáta uložené ako parametre zvukového modelu, ktorý je možné následne kontrolovať. To je však náročnejšie na výkon a nie vždy je dosiahnutý lepší výsledok, ako pri špičkovej konkatenančnej syntéze.
Na súčasných asistentoch, ako je Amazon Echo a pred niekoľkými mesiacmi aj Google Home si môžete vychutnať extrémne dobrú syntézu hlasu, ktorá v základe pôsobí veľmi ľudsky. Behom chvíľky si ale uvedomíte, že o človeka nejde, pričom hlavnými rozlišovacími prvkami je horšia intonácia a miestami neprirodzené skrátenie niektorých slabík. Tie sa miestami akoby prevrátia naruby a znejú veľmi neprirodzene. Aj keď je teda napríklad 90 % celej vety znie veľmi dobre, drobné chyby v zostávajúcich 10 % syntézu vždy prezradia.
Prielom v tomto smere priniesli konvolučné neurónové siete, pričom súčasnou špičkou v obore je predovšetkým vývojový tím Googlu (Alfabetu), respektíve jeho dcérska spoločnosť DeepMind, stojaca za rôznymi systémami umelej inteligencie. Tá pred viac ako rokom zaujala výbornými výsledkami so svojim systémom WaveNet, ktorý používa konvolučné neurónovej siete, generujúce zvukovú krivku do prirodzenejšej podoby.
Systém tohto typu je kŕmený veľkým množstvom zvukových dát, na základe čoho sa učí, ako má reč vyzerať a akými pravidlami sa riadi. Neurónová sieť následne sama vytvára kostru, ako je potrebné zvukové vzorky správne upraviť, aby pri kombinácii dosahovali podobný výstup, aký má človek. Rozdiel oproti stávajúcim riešeniam je masívny, pričom je ho pravdaže nutné počuť na vlastné uši. Súpravu hlasových ukážok si môžete pustiť v našom webovom článku Hlasová syntéza prešla do ultimátnej úrovne. Vitajte v novej ére.
Generovanie rôznych hlasov súčasnými neurónovými sieťami
Problémom ešte zhruba pred rokom bolo to, že tieto systémy boli mimoriadne výpočtovo náročné. WaveNet dosahoval síce výrazne lepšie výsledky, ako bežné postupy, ale ich aplikovanie v koncových produktoch, kde sa pracuje v reálnom čase a na nie príliš výkonnom hardvéri, nebolo ešte možné. To sa však vďaka vývoju zmenilo v posledných mesiacoch a Google na sklonku minulého roka začal tieto systémy integrovať do svojho asistenta, dostupného na smartfónoch, reproduktoroch či iných zaradeniach s Androidom (v angličtine a japončine).
Vývoj tu však nekončil. Aj keď aktuálny výstup produkovaný neurónovou sieťou WaveNet je takmer dokonalý a na nerozpoznanie od človeka, stále má mnohé slabiny. Ide predovšetkým o veľkú podobnosť a strojenosť výstupu. Ak sa asistenta spýtate na rovnaké otázky, jeho odpovede budú znieť neustále rovnako. Na drobnú variabilitu v hlase, akú má človek pri opakovaní tých istých viet, môžete zabudnúť.
Google však v tomto smere napreduje rýchlym tempom, pričom aktuálny stav tejto technológie sme mohli vidieť na dvoch vedeckej publikáciách z marca tohto roku (Towards End-to-End Prosody Transfer for Expressive Speech Synthesis with Tacotron, Style Tokens: Unsupervised Style Modeling, Control and Transfer in End-to-End Speech Synthesis). V rámci nich môžeme počuť masívny pokrok pri generovaní umelých prízvukov a predovšetkým celkom novú pokročilú reprezentáciu dôrazu na jednotlivé slová.
Ak bežný človek chce vo vete niečo zdôrazniť, použije v konkrétnych slovách vety zmenu intonácie, pričom imitáciu tohto efektu Google používa nový systém umelej inteligencie, nazvaný ako Tacotron 2. Podobné schopnosti mala už aj staršia verzia, avšak tá nedokázala produkovať také kvalitné zvukové výstupy, ako WaveNet. Tacotron 2, používajúci kombinácie konvolučných a rekurentných neurónových sietí, však umožňuje zmenu intonácie pri kvalite výstupu WaveNetu a výsledky sú v skutku dych berúce a je prakticky nemožné rozpoznať, že nejde o hovor ozajstného človeka. Ak chcete rozdiel počuť na vlastné uši, ukážky nájdete v článku (na získanie dobrej predstavy je vhodné vypočuť si ukážky).
Prvý a tretia ukážka je čítaná človekom, druhá a štvrtá je v jeho hlase plne generovaná neurónovými sieťami Tecatron2/WaveNet.
To, že dnes sa dostávame na úroveň, kedy je syntetizovaný hlas na nerozpoznanie o človeka, je dôležité, ale z hľadiska vytvárania falzifikátov konkrétnych osôb, podľa možností v reálnom čase, je ešte v ceste prekážka v podobe dlhého tréningu. Súčasné neurónové siete sú trénované na reálnych zvukoch konkrétnych osôb, pričom tieto zvukové dáta sa aj používajú na následnú syntézu. Na príkladoch ako je Tecotron 2 môže počuť, že zvuk je možné výrazne alternovať a vytvárať odlišné prízvuky a osoby, avšak vytvárať kompletnú identickú kópiu tej konkrétnej je vec iná. I keď na začiatku tréningu je vždy skutočná osoba, dnešné systémy vyžadujú obrovské množstvo referenčného materiálu a takisto expertný dohľad, pri ktorom sa hlasy podobne analyzujú a výsledok sa piluje do správnej podoby.
Nemusí však ale už trvať dlho, kedy budú k dispozícií systémy umelej inteligencie, ktoré zvládnu skopírovať dokonale hlas osoby na základe rýchlej, krátkej a hlavne plne autonómnej analýzy. V marci tohto roku sa svojimi výsledkami pochválil čínsky ekvivalent Googlu, Baidu. Jeho vývojový tím vedie významný vývojár neurónových sietí Andrew Ng Yan-tak, profesor Stanfordovej univerzity, ktorý má pod palcom vývojársku odnož Baidu sídliacu v Silicon Valley. Ide o projekt Deep Voice ktorý už minulý rok predvádzal úctyhodné výsledky pri zhruba tridsať minútovom tréningu. Behom posledných mesiacov sa však systém zlepšil na toľko, že podobné výsledky dokáže vykonať z niekoľkých sekúnd audio záznamu.
Na štvorsekundovej ukážke môžete počuť ženu, ktorá hovorí „povedz jej, aby tie veci priniesla z obchodu“. Táto ukážka je následne poskytnutá systému umelej inteligencie, pričom neurónová sieť vyprodukuje vetu „prokurátori zahájili masívne vyšetrovanie v súvislosti s podvodom v hrách“. Hlas znie nepríjemne roboticky, avšak podobnosť je jasne badateľná.
Napodobenie hlasu na základe len 7 minút počutia
Ak by vám niekto povedal, že ide o hlas tej istej ženy, ale masívne skomprimovaný do nízkej kvality, pravdepodobne by ste aj uverili. Robotickosť je pravdaže stále počuť a pripomína čistý výstup systému Tecotron od Googlu, pred vyhladením cez „WaveNet vrstvu“. To, že tak dobrý zvukový výsledok je vyprodukovaný na základe necelých 7 minút počutia je však celkom úžasný fakt a prezrádza nám pomerne jasne to, že kompletná kópia akéhokoľvek hlasu na počkanie bude vykonateľná len do niekoľkých rokov.
Táto technológia pri tom nebude úzko strážená a nebudú ju mať len tie najväčšie IT firmy, ktoré ju budú používať vo svojich produktoch. To ani zďaleka. Napríklad Adobe v súčasnosti vyvíja program, pod kódovým označením Project VoCo, ktorý by mal byť pre hlas de facto totožným editorom, ako je dnes Photoshop pre rastrové obrázky. V rámci neho bude možné rýchlo vziať nahraný hlas človeka a doplniť do neho napríklad slová a vety, ktoré nikdy nepovedal. Produkovať umelý hlas kohokoľvek bude skrátka už o pár rokov triviálna záležitosť. Bude stačiť len analyzovať originál a vytvoriť jeho kópiu, ktorá prečíta ľubovoľný text tak ako len chcete, na nerozpoznanie od pôvodnej osoby.
Porno hviezdou proti svojej vlastnej vôli
Vykonať skutočne vierohodný prenos tváre do postavy inej osoby, bolo v dávnejšej minulosti náročná úloha pre ľudí z oblasti digitálnych efektov v rámci kinematografie. Zhruba za posledných päť rokov sa však hlavne do mobilnej sféry začali vkrádať rozličné zábavné technológie pomerne jednoduchej „výmeny tváre“, v angličtine ako označované ako Face Swap (rovnako sa volala aj prvá populárna aplikácia dostupná pre iOS), umožňujúce rýchlo vymeniť tvár napríklad s priateľom pri pohľade do selfie kamery smartfónu.
Veľkú popularitu tento trend nabral najmä v roku 2016, kedy sa mechanizmy tohto typu objavili napríklad v rámci aplikácie Snapchat a ďalších. Kvalita týchto riešení sa v posledných dvoch rokoch zlepšila hlavne vďaka zapracovaniu lepších neurónových sietí, natrénovaných na tento typ úlohy.
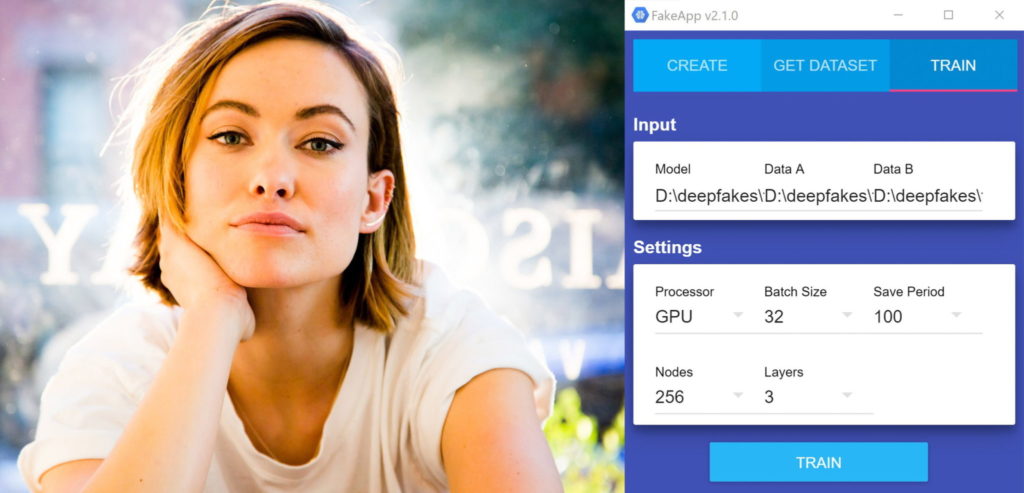
Častým cieľom aplikácie FakeApp (rozhranie vpravo) je herečka Gal Gadot
Tieto technológie môžu byť použité aj v rámci umiestňovania tváre „nevinnej“ osoby do rôznych šteklivých pozícií. Je totiž jasné, že ak je možné pohodlne vymeniť tváre dvoch osôb na videu pred selfie kamerou, je možné tak isto vymeniť aj tvár celebrity napríklad s herečkou v porno videu.
Tento typ úlohy je však značne komplexnejší. Kým pri štandardnom „Face Swape“ tvár osôb zaberá prakticky celú plochu videa, osoby sa obvykle príliš nehýbu a obe sú v podobnej vzdialenosti a pozerajú sa rovno do kamery, tak v rámci nesúvisiaceho pornografického či iného videa je hlava osoby v rozličných častiach obrazu, v takmer neprestajnom pohybe, rozličných náklonoch a v odlišnom nasvietení a podobne. Výmenný mechanizmus musí teda tvár podrobne analyzovať a alternovať podľa rozličných zmien.
Neurónové siete sú toho schopné, pričom pre produkovaný obsah tohto typu sa vžilo označenie Deepfakes. Ide o zloženie anglických slov fakes (podvrhy) a deep (hlboký), čo je narážkou na metódy hlbokého strojového učenia, do ktorých spadajú moderné neurónové siete. Pornografické videá vytvorené týmto spôsobom sa začali v hojnej miere objavovať na internete koncom minulého roku (predovšetkým na sociálnom portáli Reddit), pričom ozajstný boom nastal v prvých mesiacoch roku 2018.
V drvivej väčšine prípadov bola na ich výrobu použitá bezplatná desktopová aplikácia FakeApp (www.fakeapp.org/download), ktorá je dostupná od januára. Je založená na softvérovej knižnici TensorFlow od Googlu, určenou pre strojové učenie a neurónové siete, ktorú pôvodne vyvinul tím Google Brain pre interné účely firmy. Od roku 2015 je však TensorFlow dostupný s otvoreným zdrojovým kódom pre kohokoľvek.
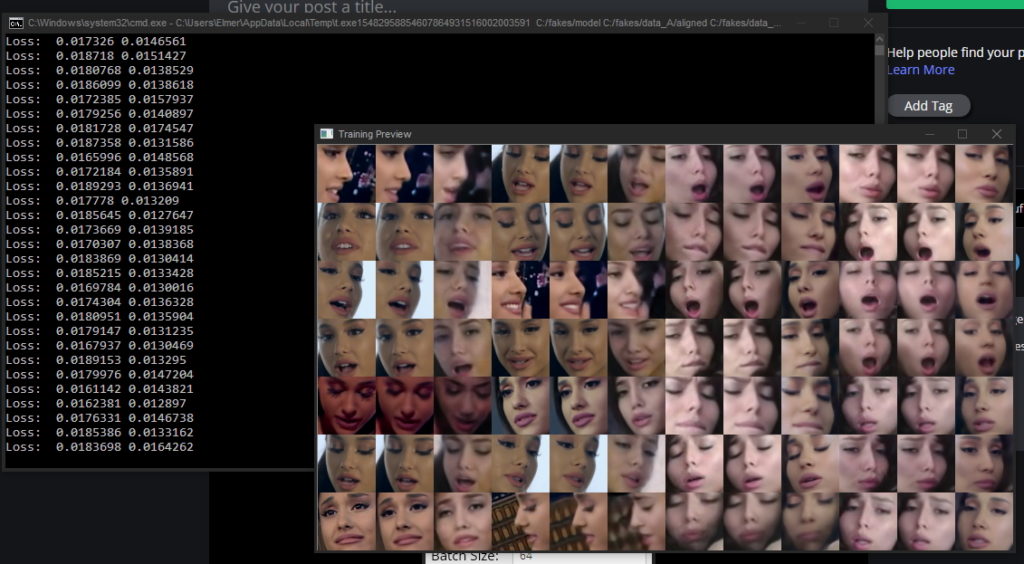
Automatické rozsnímkovanie videa na jednotlivé polohy tváre pre tréning neurónovej siete
Aplikácia FakeApp, od neznámeho autora, umožnila tieto videá jednoducho vytvárať aj úplným začiatočníkom. Kvalita výsledkov sa tak výrazne líši, podľa toho ako mala tá či oná osoba cit pre výber zdrojových a cieľových materiálov. Kým niektoré videá tohto typu sú smiešne nepresné a plné chýb, iné sú takmer dokonalé a je ťažké si uvedomiť, že ide o podvrh. Základom je vybrať pornografické video, v ktorom má porno herečka podobnú postavu a účes, ako cieľová celebrita.
Následne je potrebné mať dostatok videí celebrity vo veľkom množstve uhlov jej tváre. Obvyklou slabinou je v tomto ohľade malá dostupnosť záberov z vyššieho uhlu (z hora takmer kolmo dole), čo je typ záberu prítomný v pornografii v hojnom množstve. Vybraté zdrojové videá celebrity v dostatočnej kvalite (kde je ideálne jediná tvár v zábere) a zároveň cieľové porno video softvér automaticky rozoberie na desaťtisíce jednotlivých snímok tvárí, pričom hľadá podobné uhly.
Následne sa vykoná tréning neurónovej siete, ktorá sa snaží tvár (obvykle hlavne nos a oči) správne zakomponovať do videa, pričom upravuje nasvietenie a polohu zdrojového materiálu. Keďže automatický tréning môže trvať aj na výkonom domácom PC niekoľko hodín, deepfake videá sú často pomerne krátke a trvajú len pár sekúnd či 1 až 2 minúty. Ide však len o limit investovaného času, ktorý obyčajný človek do procesu vloží, nejde o limit technológie ako takej.
Namapovanie tváre Gal Godot na telo inej osoby neurónovou sieťou (obsahuje nahotu)
Prítomnosť čoraz kvalitnejších videí s tvárami celebrít vyústila do mediálneho poprasku, pričom tlak bol natoľko silný, že Reddit používateľskú skupinu venovanú tomuto obsahu vo februári vymazal (subreddit deepfakes a niekoľko ďalších). Ban na tento obsah vyhlásila takisto aj najväčšia porno stránka na svete v podobe Pornhubu, avšak v súčasnosti už tento zákaz príliš uplatňovaný nie je.
Dôvodom zákazu malo byť v oboch prípadoch to, že firmy nepodporujú „involuntary pornography“, teda v preklade nedobrovoľnú pornografiu. V súvislosti s mediálnou kritikou sa dala celá problematika chápať ako morálny problém, pretože dané herečky, speváčky a iné celebrity sa z určitého pohľadu stávali porno herečkami proti svojej vlastnej vôli.
Reakcia tohto typu bola nepochybne zaujímavá, pretože falošná pornografia celebrít, či už v podobe photoshopom upravených fotografií, alebo videí v ktorých vystupovali skrátka len podobné herečky, existuje dekády bez nejakej zvláštnej pozornosti a veľkej morálnej debaty. Mnohých ľudí presvedčivosť niektorých videí skrátka zaskočila a nečakali, že by súčasné technológie už také niečo umožňovali vytvárať prakticky komukoľvek a to aj úplným amatérom na počkanie.
Faktom ale je, že nasledujúca dekáda bude v tomto vskutku prelomová a nástupu tohto trendu nie je možné nijako zabrániť. Tak ako by bolo absurdné, snažiť sa dnes držať pod kontrolou a likvidovať na internete upravené fotografie, kde sa na cudzie nahé telo zručne zakomponuje tvár nejakej celebrity, tak bude márne snažiť sa poľovať po ekvivalentných videách. Ich objem bude totiž priveľký a miera potrebných schopností na ich vytvorenie primalá.
Pre zrýchlenie narábania s veľkým objemom grafickej informácie je vhodné používať GPU výkonnej grafickej karty
Automatický systém bude len potrebné nakŕmiť správnymi dátami, čo zvládne každý. Pre dotknuté osoby na videách to bude nepochybne nepríjemné, ale v konečnom dôsledku nejde o nový princíp. Napr. konkrétnych politikov môže rozčuľovať, že si o nich celá populácia rozpráva vtipy a zosmiešňuje ich v rôznych paródiách, ale v demokratických a slobodných krajinách ide o fakt, ktorý je bremenom danej práce.
Byť celebritou, ktorá je cieľom „porno“ úprav, je značne podobné. Netýka sa to pravdaže len ich. Ako bude vývoj technológií pokračovať, potreba dlhého tréningu neurónovej siete bude čoraz menšia. Okrem celebrít si tak možno predstaviť aj dobu, v ktorej si mnohí ľudia dosadia do porno videa napríklad svoju školskú lásku či kolegyňu z práce. Bude stačiť len krátky videozáznam z telefónu.
Už onedlho bude vytvorenie prakticky dokonalého videa tohto typu také triviálne, ako je dnes použitie video filtru, ktorý osobe pridá kreslené fúziky či mačacie uši, pohybujúce sa spolu s hlavou v reálnom čase. Snažiť sa aby čoraz lepšie technológie na výmenu tváre dvoch osôb nikdy neboli použité na pornografiu, je ako snažiť sa aby neexistovali pri klasických magazínoch aj porno magazíny a popri klasických filmoch aj porno filmy (v histórii poznáme neúspešnú snahu tomu zabrániť v oboch prípadoch). Je to skrátka márny boj.
FakeApp je možné použiť aj na zábavné účely, ako napríklad aplikovanie herca Nicolasa Cagea do podoby kapitána Picarda zo StarTreku či Lois Laneovej zo Supermana
Z hľadiska zákonov bude pravdaže vhodné rozlišovať medzi vopred odhaleným trikom a pokusom o podvod. Ak niekto uverejní video tohto typu s tým, že ide o fikciu, je to odlišné od prípadu, kedy by sa dané video používalo s cieleným účelom niekoho oklamať a danú imitovanú osobu poškodiť. To je dôležité v súvislosti s pornografickými i nepornografickými videami. S pribúdajúcimi rokmi a dekádami skrátka budú video podvody na nerozpoznanie od regulárnych video záznamov.
A to môže viesť k masívnemu rozšíreniu nedôvery v rámci akéhokoľvek multimediálneho obsahu. Bude totiž možné efektívne a presvedčivo šíriť nepravdu viac, ako kedykoľvek predtým, pričom to otvorí celkom nové dvere v rámci efektívnej propagandy. Šírenie falošných správ, najmä pomocou zdieľania na sociálnych sieťach, sa znásobí, pretože nové podvody z hľadiska falošných „uniknutých záznamov“ budú môcť oklamať nielen bežného človeka, ale aj silné a dôveryhodné spravodajské organizácie.
V nadchádzajúcich rokoch začne byť pri určovaní pravosti videí potrebná expertná analýza, ktorá však bude s pribúdajúcimi rokmi čoraz zložitejšia, až napokon nemožná.
S dnešného pohľadu to vyzerá vskutku strašidelne. Spoľahlivé zdroje správ budú dôležitejšie, ako nikdy predtým. Tak to ale skrátka už býva. Nové technológie často otvárajú mnoho nových dverí a to čo je za každými sa nie všetkým musí páčiť. Často krát ale už nie je cesty späť a spoločnosť sa musí prispôsobiť na novú realitu.